
CIDR22 MMAP = 💩
- Paper Reading
- 2025-08-04
- 364 Views
- 0 Comments
- 1556 Words
Are You Sure You Want to Use MMAP in Your Database Management System?
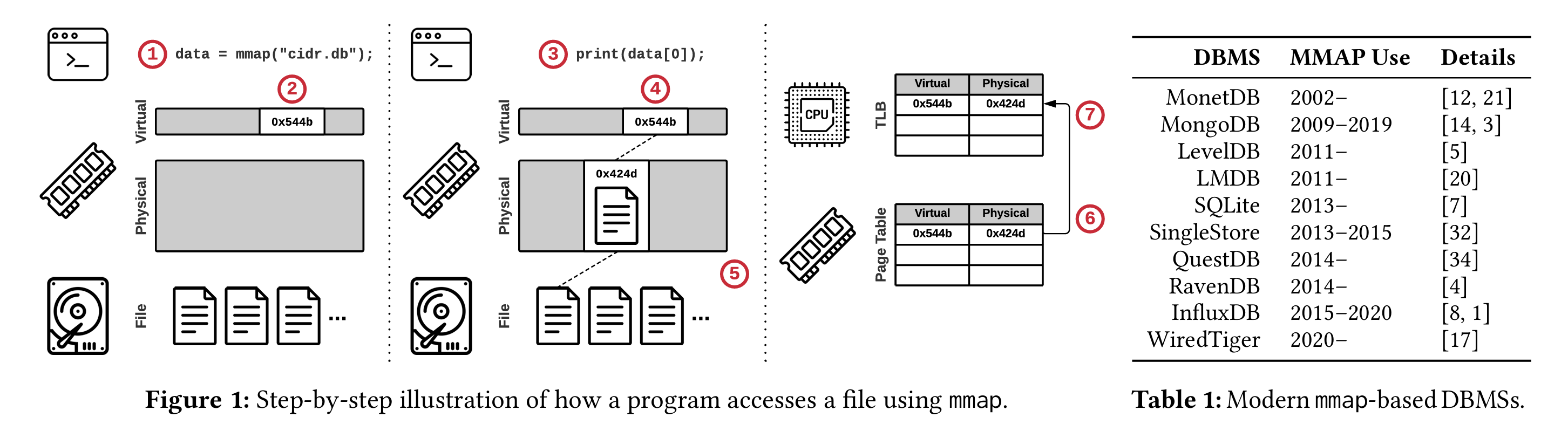
内存映射(mmap)文件 I/O 是操作系统提供的一种功能,可将二级存储上的文件内容映射到程序的地址空间中。然后,程序通过指针访问页面,就像文件完全位于内存中一样。只有当程序引用页面时,操作系统才会以透明的方式加载页面,并在内存填满时自动删除页面。
数十年来,mmap 的易用性一直吸引着数据库管理系统(DBMS)开发人员,被视为实施缓冲池的可行替代方案。然而,mmap 存在严重的正确性和性能问题,这些问题并不是一眼就能看出来的。这些问题使得在现代 DBMS 中正确、高效地使用 mmap 即使不是不可能,也是很困难的。事实上,一些流行的 DBMS 最初使用 mmap 来支持比内存更大的数据库,但很快就遇到了这些隐藏的危险,迫使它们在付出巨大的工程代价后转而自己管理文件 I/O。这样看来,mmap 和 DBMS 就像咖啡和辛辣食物:一种事后才会显现的不幸组合。
由于开发人员不断尝试在新的 DBMS 中使用 mmap,因此我们撰写了这篇文章,以警示其他人 mmap 并不适合替代传统的缓冲池。我们详细讨论了 mmap 的主要缺点,实验分析表明了其明显的性能限制。基于这些发现,我们最后为 DBMS 开发人员开出了一剂药方,即在使用 mmap 时,应将其与传统的缓冲池结合起来。
知乎刘逸群总结:
在高并发、高磁盘读写量场景下,OS现有的page cache设计是有不足的。OS page cache的通用API也不能提供对磁盘IO的精细控制。这种使用场景的应用,应当自己实现文件缓存。
这篇文章旗帜鲜明地反对在数据库中使用page cache做文件缓存(也就是mmap共享模式MAP_SHARED),其实十分切合这个题目。文章提了这么几点理由:
- 开发层面,mmap file没有完备的stage-commit API。mmap会自动把dirty page写回,你可以强制写回,但你不能要求它不写回。这对一致性控制是减分项——事务还没有commit时,中间结果可能就被持久化了。这让事务的实现更复杂了。应用自己管理缓冲区,就没有这些烦恼。
- 性能层面,mmap file也有性能局限。
- 并发:内核中page cache能提供的并发度并不一定能满足应用所需的吞吐量,内核数据结构如果成为瓶颈,开发者将束手无策。
- 吞吐量:当文件吞吐量过大时,mmap file的会频繁换入换出,换出page cache时,需要修改相关的页表和TLB。页表还好,但是TLB每个核都有一个份,这意味着换出page cache时需要同步清理全核TLB——一次全核中断,对吞吐量和时延的影响都很大。如果bypass掉OS page cache,自己管理一个恒定大小的buffer pool,这时候OS页表和TLB是不受影响的。这篇文章的实验主要在验证这一点。
- 预取,写回,换入换出等具体的策略,只能用OS提供的,虽然也有几种选择(比如
MADV_RANDOMMADV_SEQUENTIAL),但上限肯定远远比不上应用层按需定制的。
既然操作系统层已经提供了page cache的功能,为什么还要在应用层加缓存? - 刘逸群的回答 - 知乎
https://www.zhihu.com/question/29203599/answer/2984747895
论文要点:mmap不适合数据库的4个bottleneck
- Safety Trans
- I/O
- Error Handling
- Performance
来自大佬的反驳
re: Are You Sure You Want to Use MMAP in Your Database Management System? - RavenDB NoSQL Database
下面还是知乎总结
作者:刘逸群
链接:https://www.zhihu.com/question/29203599/answer/2984747895
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
开发层面
- 实现应用buffer pool比mmap复杂得多,论文对此轻描淡写。
- 论文认为DB实现xx机制是为了解决mmap带来的问题,其实并不是,是为了其他DB-specific的问题。
- mmap的对细粒度IO缺乏控制并不会显著增加编程的复杂度。数据库一般会支持更复杂的一致性模型(比如MVCC),OS page cache造成的问题其实是在实现这些模型的过程中,被顺带解决的。Postgres就是一个例子,它没有使用OS page cache。但还是会像OS page cache一样把uncommitted data持久化(从博客来看应该是在页内使用了类似shadow paging的shadow row?),换言之,有了MVCC,PG对写uncommitted data根本不care……
性能层面
-
操作系统的page eviction比应用层有更高的灵活度。OS page cache的一个页什么时候换出都可以,即使另外一个transaction还在用——大不了触发page fault后重新加载。这是对应用代码完全透明的。应用层buffer pool不能这样,换出前必须确认没有transaction还在使用本页,否则这个程序语义就直接错了。监测哪些transaction还在使用本页,这是个额外的开销也可能会成为瓶颈——多线程场景下,这涉及到刷其他核的数据缓存(和论文中提到的TLB shootdown有点类似了……)。
-
论文中提到的很多性能瓶颈都是纸上谈兵,真实DB中未必会出现。比如论文中TLB shootdown的问题,很可能是个伪瓶颈:
-
论文中TLB shootdown产生的前提是buffer写满导致了大量的换入换出。但DB对页的访问是不均匀的,多数访问可能涉及少数页(如B+树的前几层),所以需要换入的页实际上并不不多
-
大硬盘的机器也会配大内存,OS page cache的容量因此没那么容易成为瓶颈。不会有人在硬盘上很慷慨,但在内存上一毛不拔吧~