我在CPU修PMU:Can We Trust Profiling Results?
- Paper Reading
- 2025-11-11
- 393 Views
- 0 Comments
- 5964 Words
Can We Trust Profiling Results? Understanding and Fixing the Inaccuracy in Modern Profilers
https://par.nsf.gov/servlets/purl/10122098
在上次阅读完博客 # Where Do Interrupts Happen? 后(我的中文解析:https://www.haibinlaiblog.top/index.php/where-do-interrupts-happen/ ),我们了解到,这部分的内容属于 skid / precise event ,即 perf 类软件与实际执行不一致的情况。
随后,我们阅读ICS19的来自NCState的Xu Liu老师(目前老师去工业界了)的文章:Can We Trust Profiling Results? Understanding and Fixing the Inaccuracy in Modern Profilers。
文章链接:https://par.nsf.gov/servlets/purl/10122098
Intro
我们平常使用的Linux Perf、VTune等Profiler,都是使用基于性能监控单元(PMU)的统计采样方法。然而,文章写道,由于PMU设计存在固有局限,其指令测量结果存在准确性问题。
那么,这个误差到底有多大?又会如何误导我们的优化工作?最关键的是,我们能否修正它?
为了从根本上理解和解决这一精度问题,文章的研究采用以下三个清晰步骤:
- 问题量化:我们测试了多种现代处理器架构,并通过数学模型,首次精准地揭示了PMU指令分析在不同平台上的误差程度。
- 影响评估:我们构建了一个系统化的分析框架,用以客观评估上述测量误差会对性能分析结论造成多大影响,明确了修正的必要性。
- 提出解决方案:我们开发了一种创新的软件算法,能够有效校正由PMU硬件引入的误差。实际验证表明,该技术能显著提升指令 profiling 的准确性。
误差有多大?
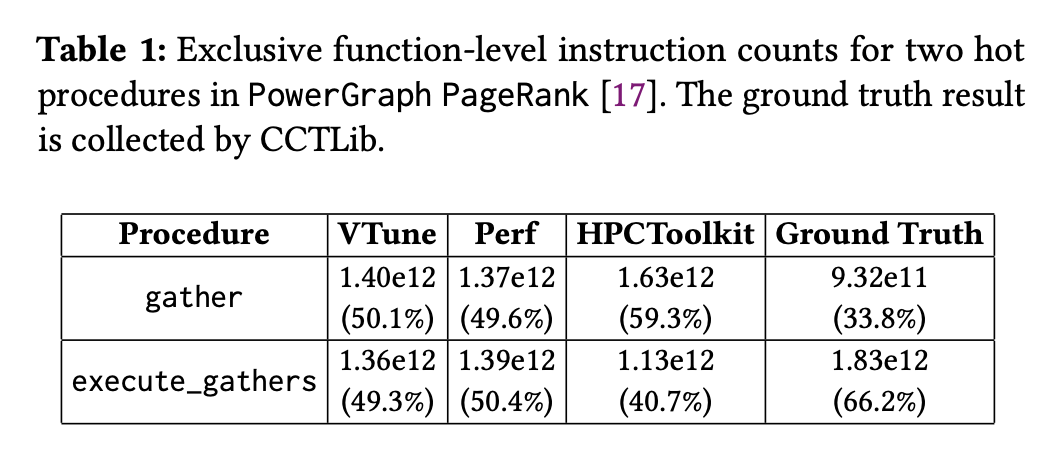
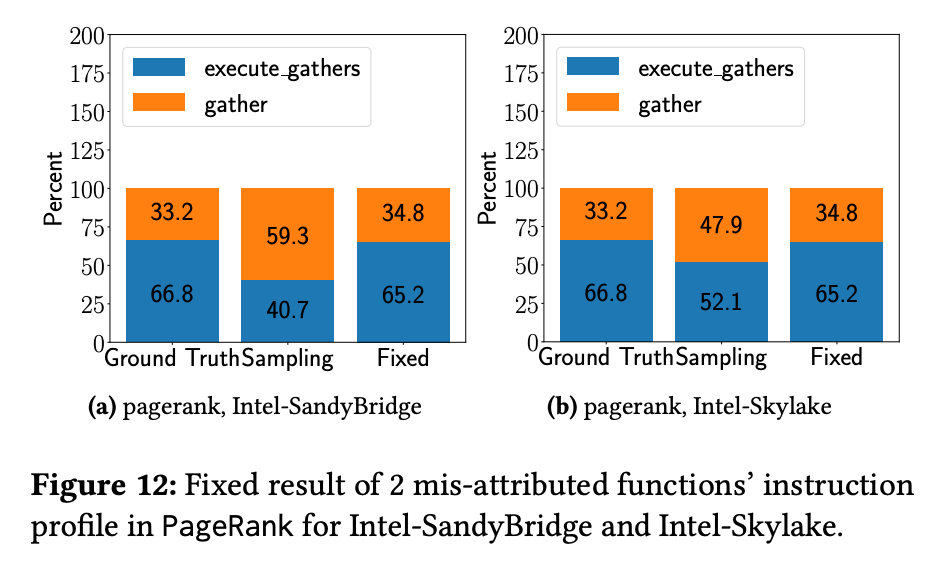
作者用VTune、Perf、HPCToolkit和Ground Truth 这4种Profiler去测量 PowerGraph PageRank程序的两个workload的执行时间和Sample情况。发现对这两个函数,他们的占总时间的比例并不相同并且相差极大(比如VTune测出来gather占50.1%时间,但是Ground Truth却说只占比33.8%)
这种测量误差就源于处理PMU样本时的硬件限制。至于这句话具体在说什么,我们需要先了解Perf等性能分析器是怎么采集出这个hotspots和执行数据的。
Profilers with PMU based Sampling 介绍
What is PMU
PMU,是硬件会提供的可以配置的性能计数器。他们会在对应的硬件事件触发时更新这些计数器,然后再由程序读取计数器的值并统计。
CPU的PMU提供了可编程方式来计数硬件事件,如已执行指令、CPU周期、缓存未命中等。当预设数量的事件发生时,PMU会触发溢出中断。运行在被监控程序地址空间的分析器能够处理该中断,并"恰当地"(真的吗?)归因测量结果。我们将PMU计数器溢出称为"样本"(Sample)。PMU普遍存在于不同厂商的CPU处理器中,如Intel、AMD、IBM和ARM。
关于PMU的更加详细的介绍,可以参考这些文章:
[perf 2] perf 后端:硬件 PMU(上) - 苏里南公牛的文章 - 知乎
https://zhuanlan.zhihu.com/p/678581172
https://jia.je/software/2024/12/10/linux-perf-pmu/#%E5%8F%82%E8%80%83
Perf采样技术与PMU的原理
Linux Perf_events 是如何收集的:Linux提供了API来配置、启用和禁用线程粒度下的PMU(例如perf_event_open,ioctl)。当PMU事件计数器溢出时,Linux内核会向对应线程发送包含事件详情(如指令指针)的信号。用户空间的信号处理程序随后检查事件信息并归因正确的测量结果。某些PMU功能(如Intel的精确基于事件采样)会分配内核缓冲区来记录多个样本,并允许工具通过poll()读取该缓冲区。
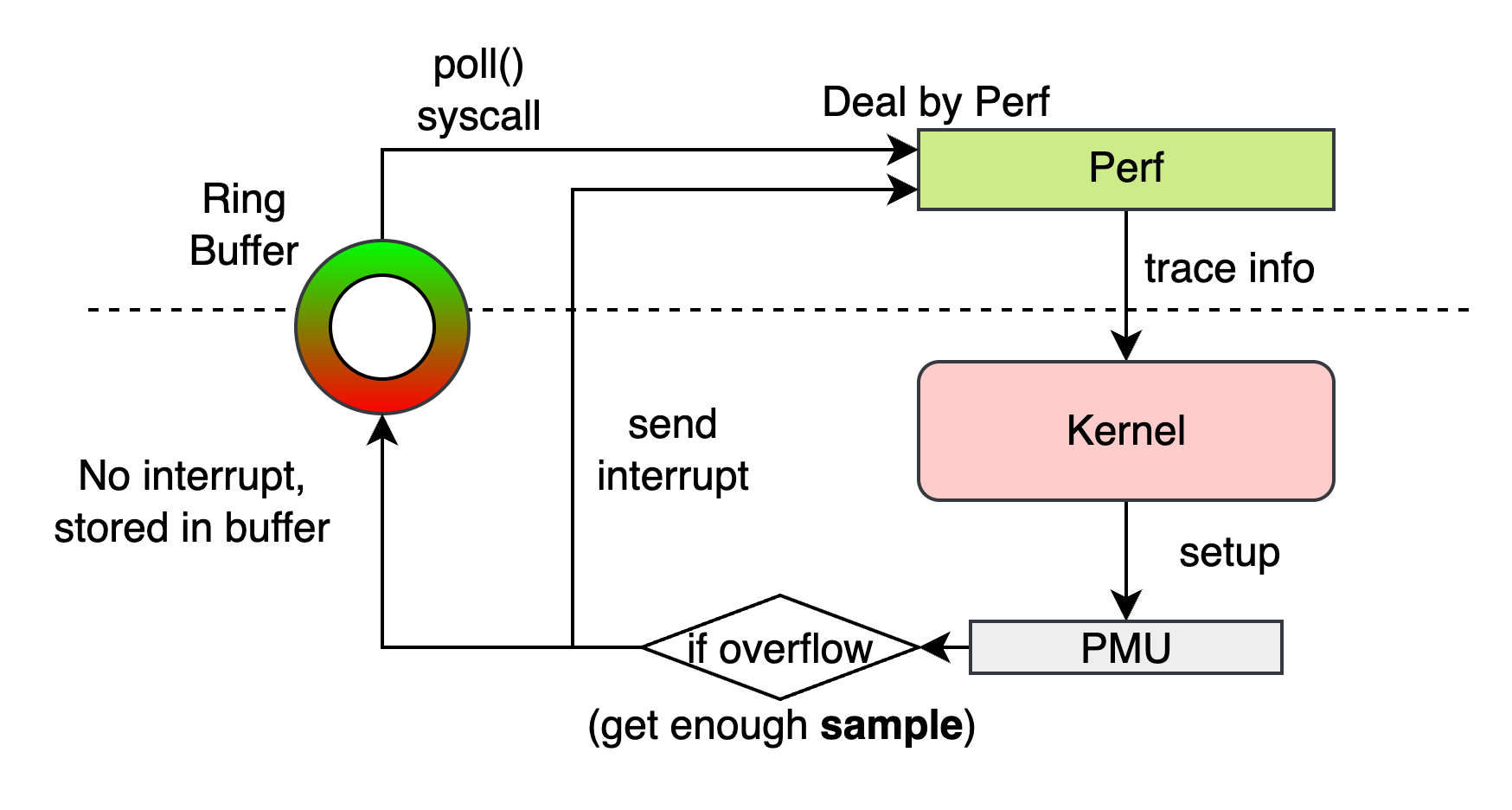
Perf_events的分析机制:许多工具采用调用路径分析,这种分析技术将运行时事件(如缓存未命中)归因于事件发生时看到的完整调用路径。对于具有深层调用链的复杂应用程序,调用路径分析能提供有深度的详细信息。事件的调用上下文是事件发生时处于活动状态的过程帧集合。调用上下文从进程或线程入口函数(如main)开始,到触发事件的指令的指令指针(IP)结束。借助调用上下文,工具能够将样本与调用链中的所有函数关联。从所有被调用函数累计的指标称为包含性指标,而不从被调用函数累计的指标称为独占性指标。
我们用采用中断的Perf方法进行讲解(GPT讲的)
-
配置与启动:
- 性能分析工具(如
perf命令)通过perf_event_open系统调用,告诉内核:“我要监控这个线程的‘已退休指令’事件,每发生 100,000 条指令就通知我一次。”(这个 100,000 就是采样周期P)。 - 内核会配置好对应的 PMU 计数器,并将其初始值设为
MAX - 100,000。
- 性能分析工具(如
-
溢出与信号触发:
- 线程开始执行。当 PMU 计数溢出时,CPU 会产生一个硬件中断。
- 内核的中断处理程序接管,它会向被监控的那个线程发送一个特殊的信号(通常是
SIGPROF或SIGIO)。
-
用户态处理:
- 这个信号会导致线程立即暂停其当前的正常执行流。
- 线程转而执行一个预先由分析工具注册好的信号处理函数。
- 在这个函数里,工具可以访问到内核传递过来的
siginfo_t结构体,其中包含了关键的样本信息,最核心的就是指令指针(IP),即事件发生时程序执行到哪一行代码了。 - 工具根据这个 IP 地址,查找调试信息,找到对应的函数名、源代码行号,然后在自己的计数表中为这个位置增加一次计数。
测量不准确的来源
在乱序处理器中,由监控事件触发的PMU计数器溢出中断可能会显著延迟。这种延迟称为"偏移",通常具有不确定性和非固定性。为简化说明,图1展示了偏移如何导致测量不准确。
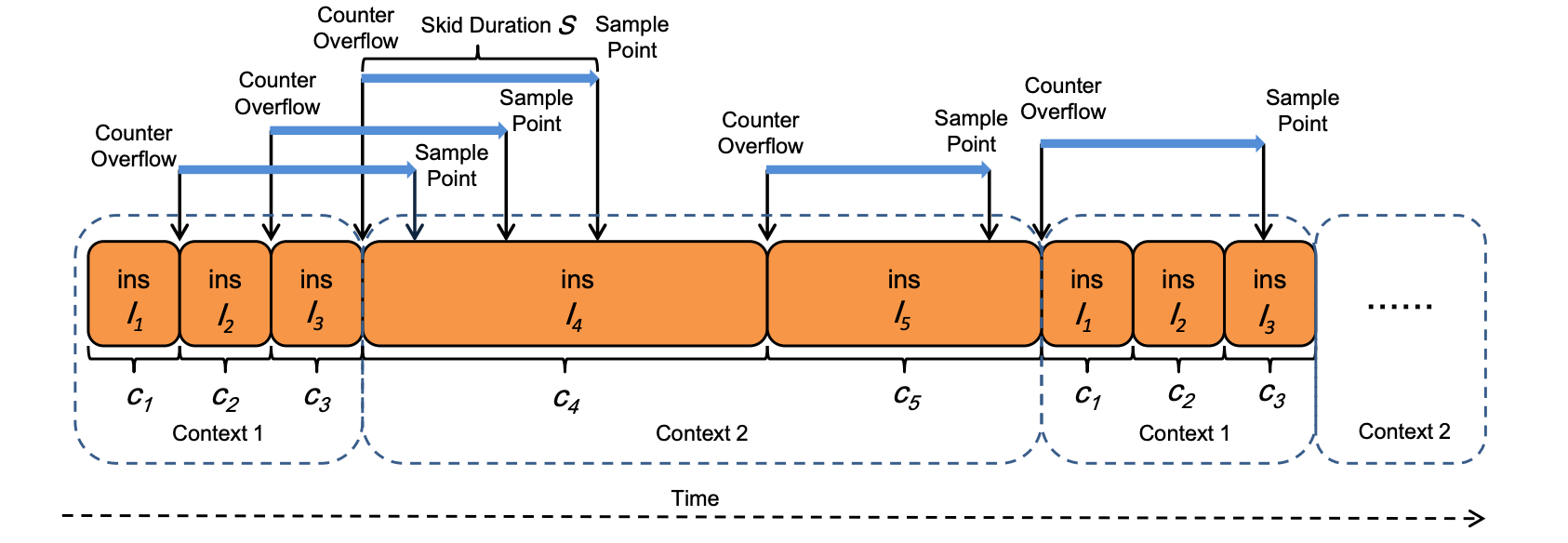
图1 的指令分析结果中的滑移效应(Skid Effect)影响:一个循环包含5条指令I1、I2……I5,这些指令分别具有不同的周期持续时间c1、c2……c5。由于滑移效应,CPU需要固定时长S来定位当前活跃指令。例如:当已退休指令I1触发指令计数器溢出后,CPU需短暂时间S才能发现I4正处于活跃状态,并将其视为采样点。 每条指令触发计数器溢出的概率相同,但被视作采样点的概率并不均等。指令I4因其周期持续时间显著长于其他指令,更可能被选为采样点。这最终会导致上下文层面的指令采样点归属偏差。
PMU profile 不准确的程度
现代CPU处理器提供了多种精确采样机制以减轻或消除滑移现象,例如英特尔的基于事件的精确采样(PEBS)和AMD的基于指令的采样(IBS)。这些机制通过专用性能监控单元(PMU)寄存器记录触发PMU计数器溢出的精确指令指针(IP)。然而,并非所有CPU供应商(如ARM)都支持这类精确机制。
更重要的是,这些机制并非总能提供可靠的分析结果:
关于IBS的缺陷:“未退休指令”问题
就IBS而言,PMU需要在指令发射阶段进行标记以监控其在流水线中的执行状态,若该指令因推测执行未能完成退休,PMU在此期间将无法捕获任何样本:
- “PMU需要在指令发射阶段进行标记”:IBS的工作方式是,当一条指令被“发射”到执行流水线时,PMU就标记它,开始监控。
- “若该指令因推测执行未能完成退休”:现代CPU为了性能,会进行“推测执行”,即提前执行一些可能需要的指令。但如果预测错误(如分支预测失败),这些被推测执行的指令就会被作废,不会“退休”(即不会被确认为有效结果)。
- “PMU在此期间将无法捕获任何样本”:如果一条被IBS标记的指令因为推测执行失败而被作废,那么PMU针对这条指令的监控就白费了。在这条指令从被标记到被作废的整个时间段内,PMU都不会记录任何采样数据。
关于PEBS的缺陷:“阴影效应”
而PEBS则存在阴影效应——当PMU选择流水线中已退休指令进行上报时,可能存在多个候选指令,但PEBS更倾向于上报执行延迟最高的指令,从而导致分析结果出现偏差:
-
“当PMU选择流水线中已退休指令进行上报时,可能存在多个候选指令”:在一条指令退休并触发PEBS时,流水线里可能同时有其他指令也正在退休或刚刚退休。
-
“PEBS更倾向于上报执行延迟最高的指令”:PEBS机制存在一个倾向性,它不会随机或平均地报告这些候选指令,而是会优先报告那个执行时间最长的指令。
-
“从而导致分析结果出现偏差”:这就像是一个“会哭的孩子有奶吃”的机制。执行时间长的指令(可能是因为等待数据、或本身计算复杂)会被过度报告,而执行时间短的指令则被低估。
为验证PEBS输出结果的不可靠性,我们对比了PEBS与传统PMU生成的性能分析数据。实验采用第3节介绍的微基准测试程序,每个程序包含g()和f()两个函数,其指令数分别为N_g和N_f。通过测量数据量化分析函数g()和f()中存在的精度损失(分别对应N_g+E和N_f-E条指令,其中E为误差值)。图2展示了在不同规模的g()和f()函数下,PEBS与传统PMU对所有微基准测试的误差E。实验表明:传统PMU因滑移效应产生的误差具有一致性和可预测性,而PEBS则会出现难以与真实情况关联的不可预测结果。
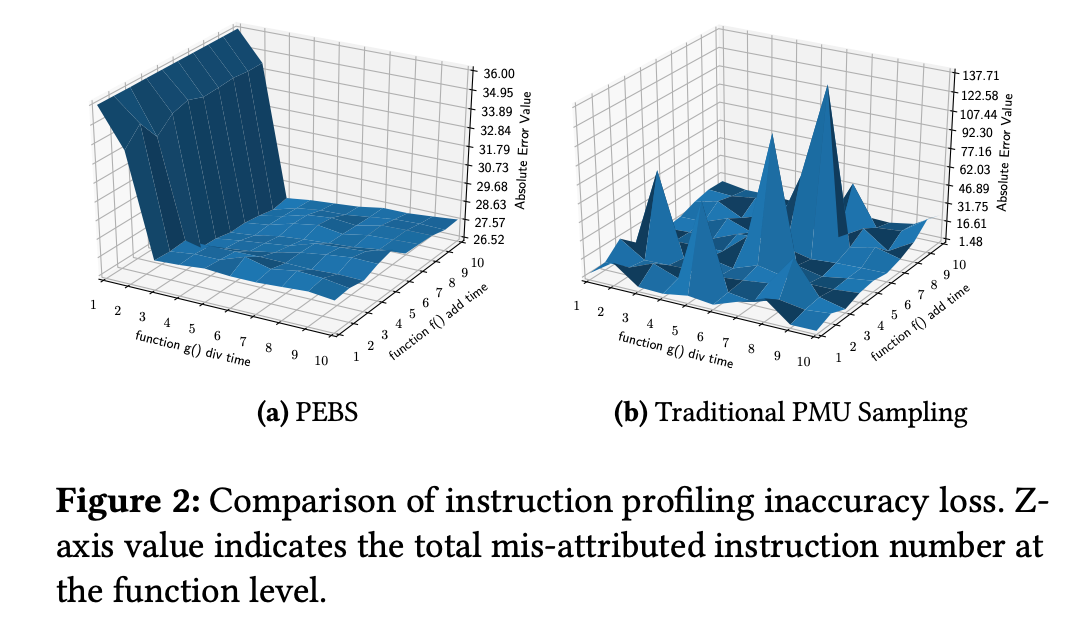
基于通用性考量,本研究将聚焦于应用广泛的传统PMU机制,而非特殊设计的精确PMU方案。
模拟/基准剖析器
我们无法依赖性能监控单元(PMU)来收集基准数据。作为替代方案,研究者可采用模拟器来测量硬件相关事件(如时钟周期、缓存未命中)。但由于难以精确模拟处理器的所有特性,模拟器可能无法为这些事件提供真实的基准值。我们注意到,与软件相关的事件(如已执行指令数和浮点运算次数)并不依赖于硬件特性。因此我们采用纯软件方法收集这类软件相关事件的基准剖析数据,该方法具有跨硬件平台的普适性。
基于此,我们开发了一款基于纯软件方法的工具,用于在调用上下文中统计过程(函数)的已执行指令数。该工具基于CCTLib构建——这是一个能确定并行程序中每条被监控指令调用上下文的Pin工具。我们在CCTLib之上设计了一个客户端工具,通过动态插桩技术精确统计每个过程在其调用上下文中的已执行指令数。
量化划移效应
本节提出一个数学模型,用于量化仅包含简单指令循环的程序中的滑移效应。
定义3.1 简单指令循环:指由固定数量指令组成的重复执行循环,除循环控制条件分支外不包含其他条件分支。
该数学模型基于以下假设:
- 滑移效应可用CPU时钟周期量化
- 每条指令的平均执行周期数固定(即CPI保持恒定)
- CPU可同时发射多条指令
- 采用周期采样时,每个周期触发硬件事件计数器溢出的概率相同,与当前执行指令无关
据此我们得出两个重要结论。
首先,滑移效应在CPU周期剖析中有一个关键特性:它不会改变最终的统计结果。这看似有悖直觉——滑移确实会导致采样点被错误地归属到不同的指令上。但作者通过一个动态平衡模型阐明,由于采样基于严格按时间推进的CPU周期,某条指令因滑移而“损失”的采样点,会恰好被其他指令“补偿”回来。
例如,指令A末尾因滑移而“逃掉”的采样点,会由指令B开头“多出来”的采样点弥补给A。这种机制确保了每条指令被记录到的采样点总数,严格正比于其真实消耗的CPU周期数。
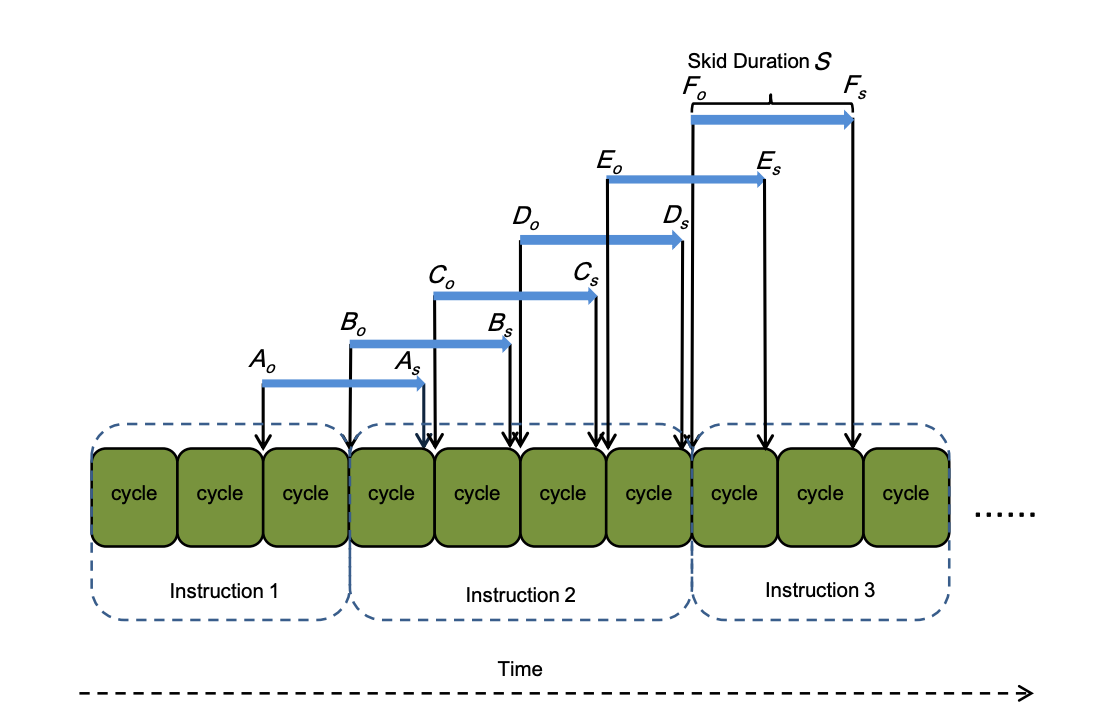
该图示具体揭示了CPU周期剖析中滑移效应的作用机制:在一个顺序执行指令的流水线中,当性能计数器在某个CPU周期结束时溢出时(即“计数器溢出点”),由于存在短于2个周期的滑移,该事件最终被记录并归因于下一条或下下条指令的时刻(即“样本点”)。例如,本由指令2触发的溢出点Co,其样本点Cs因滑移而落在了指令3上,导致了采样归属的错位。然而,这种错位是双向的——指令2在“丢失”一个样本的同时,也会从指令1那里“获得”一个因滑移而提前归属的样本。这种得失平衡机制,确保了从宏观统计上看,每条指令被记录到的总样本数与其消耗的CPU周期数始终保持正比,从而维系了周期剖析结果的最终准确性。
其次,周期剖析结果不受指令级并行(ILP)影响。核心原因在于,当采用性能计数器进行周期采样时,CPU内置机制会实时确定采样点对应的执行指令。每条指令在采样点被记录的概率取决于CPU的PMU设计,且不受滑移效应影响。由于滑移仅等效延长采样周期,而采样周期改变不会影响剖析结果,因此指令级并行在滑移存在时不会对周期剖析产生额外影响。
划移模型情况复刻:CPI不一样
我们通过一个包含五条指令(I1至I5)的简单循环来演示滑移效应模型。各指令具有不同的CPI值(c1至c5)。如图4所示,我们针对不同滑移周期S进行了仿真实验:当采用固定采样率进行指令采样时,每条指令触发性能计数器溢出的概率均等。当某条指令引起计数器溢出后,需经过S个CPU周期(滑移时长)才能完成采样点记录,此时被记录的指令可能已非原始触发指令。通过建立从触发指令到实际记录指令的映射关系,结合已知的CPI信息,即可推导出特定滑移周期下的指令分布D(S, [c1,c2,c3,c4,c5])。图4中三种滑移值的仿真结果产生了不同的分布形态,其中滑移仿真(2)得到的分布[0,2,0,2,1]与实际剖析结果D完全吻合。
基于上述特性,我们构建了通过CPI向量c与实测分布D反推滑移时长S的测量算法(详见下节)。完整的数学模型已在我们补充文档[1]的第1节中给出。
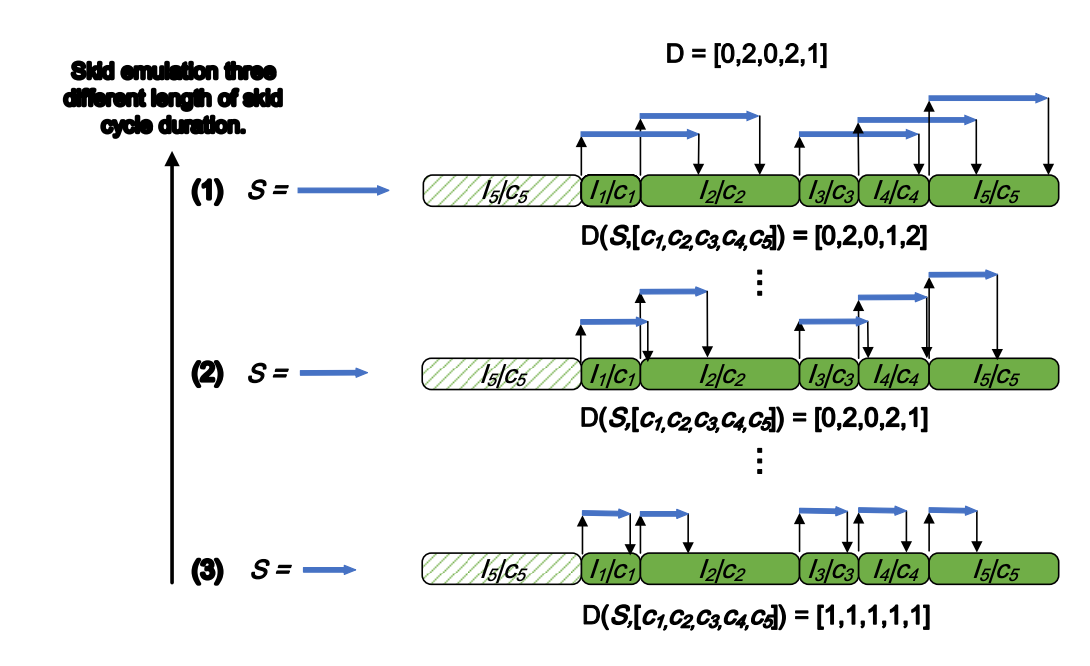
在由五条指令构成的简单循环上,使用三种不同滑移值进行滑移效应仿真的结果。每次仿真会生成一个指令分布D(S, [c1,c2,c3,c4,c5]),该分布是以各指令采样数为分量构成的向量,其中D表示实际的指令剖析结果。
怎么解决划移:校准Skid
我们技术的核心是一个校准过程。我们首先通过精巧的微型基准程序测量出该CPU平台固有的Skid值(S),将其作为一个已知常数。 然后,对于真实程序,我们将其分解,并利用PMU提供的准确的周期采样数据作为锚点,构建一个数学模型来模拟Skid如何扭曲了指令采样。通过优化算法,我们反推出最能解释当前扭曲数据的那组真实执行频率,从而校准初始的测量结果。
第一步:校准阶段(在真实硬件上)
我们先用一系列简单程序在真实的目标CPU机器上运行,同时收集它的周期和指令采样数据。然后通过我们的数学模型(软件仿真),推算出这个CPU特有的划移值S。这个过程就像为这个CPU测量出了它的“系统误差”参数。
第二步:修正阶段(在真实硬件上)
当分析一个真实复杂程序时,我们同样在同一台真实机器上运行它,收集其原始的、带有误差的PMU采样数据。然后,我们代入第一步测得的划移值S,通过优化算法,从失真的数据中反推出程序执行的真实情况(如各部分的真实执行频率)。
怎么做到的?
这里用到了一个非常巧妙的观察:虽然Skid会影响指令采样的分布,但它不会影响CPU周期采样的分布。 这意味着什么呢?
- 指令采样(被Skid影响):PMU对执行的指令进行采样,但由于Skid,采样点可能会“滑”到下一条或下几条指令上,导致记录的指令分布失真。它提供了一个被污染的、关于“哪些指令被执行”的分布图。
- 周期采样(不受Skid影响):PMU对CPU周期进行采样。论文通过模型证明,Skid效应仅仅相当于增大了采样周期,而不会改变每个指令最终“认领”到的周期样本数量。因此,周期采样的结果是准确的。从准确的周期采样中,我们可以可靠地计算出每个指令消耗的平均周期(CPI)。这为我们提供了程序执行的“物理时间尺”。
基于这个观察,我们可以从准确的周期采样结果中,找到一个Skid值(S),使得当我们用这个S值去扭曲第一步中得到的可靠CPI信息时,产生的“扭曲后的指令分布预测”,能够与第二步中实际观测到的“被污染的指令分布”最大限度地匹配。,反推出每条指令的平均执行周期(CPI)。
所以,我们可以从准确的周期采样结果中,计算出简单循环内每条指令的平均执行周期(CPI),构建出CPI向量 c。随后,通过skid模型模拟在不同skid周期值 S 下应得的指令分布 D(S, c),并将其与实际观测到的指令采样分布 D 进行比较。(具体公式可看文章)
公式2:计算模拟与实测的误差
对于一个基准程序,其误差定义为:
Error(c, S) = || D(S, c) - D ||₂
求解过程与实际测量
测量过程转化为一个优化问题:在大量结构各异的简单循环程序上,寻找那个能使总模拟误差最小的 S 值。通过求解公式 argminₛ Σ Error(cₘ, S),即可确定该CPU平台固有的skid周期。

算法1描述了我们在特定平台上测量滑移时长的方法。我们以穷举方式将S值从0遍历至300(第3行)。针对每个S值,程序会在所有测试程序上模拟滑id效应,并按照公式1累计误差总和(第4-8行)。当某S值对应的误差总和达到当前观测最小值时,该值将被记录为候选结果(第9-12行)。

图5展示了五种硬件平台(AMD-Opteron、Intel-SandyBridge、Intel-Broadwell、Intel-Skylake和Intel-Xeon Phi)在S值从0变化至300时的误差总和曲线。每个平台均可观测到一个误差全局最小点,其对应的S值即为能使误差最小化的滑移时长。该测量过程针对特定CPU平台仅需执行一次,约花费10分钟完成所有微型基准测试并搜索最优值。如我们此前讨论,最小点对应的S值即为该平台的滑移时长。所有英特尔CPU的滑移时长均小于20个周期,而AMD-Opteron平台的滑移时长显著更长,达到34个周期。
实验成功测得了多种架构的skid值,例如Intel CPU通常小于20周期,而AMD Opteron则长达34周期。这一结果为后续纯软件方案修正性能分析结果提供了至关重要的硬件常数输入。
复杂软件修正方案
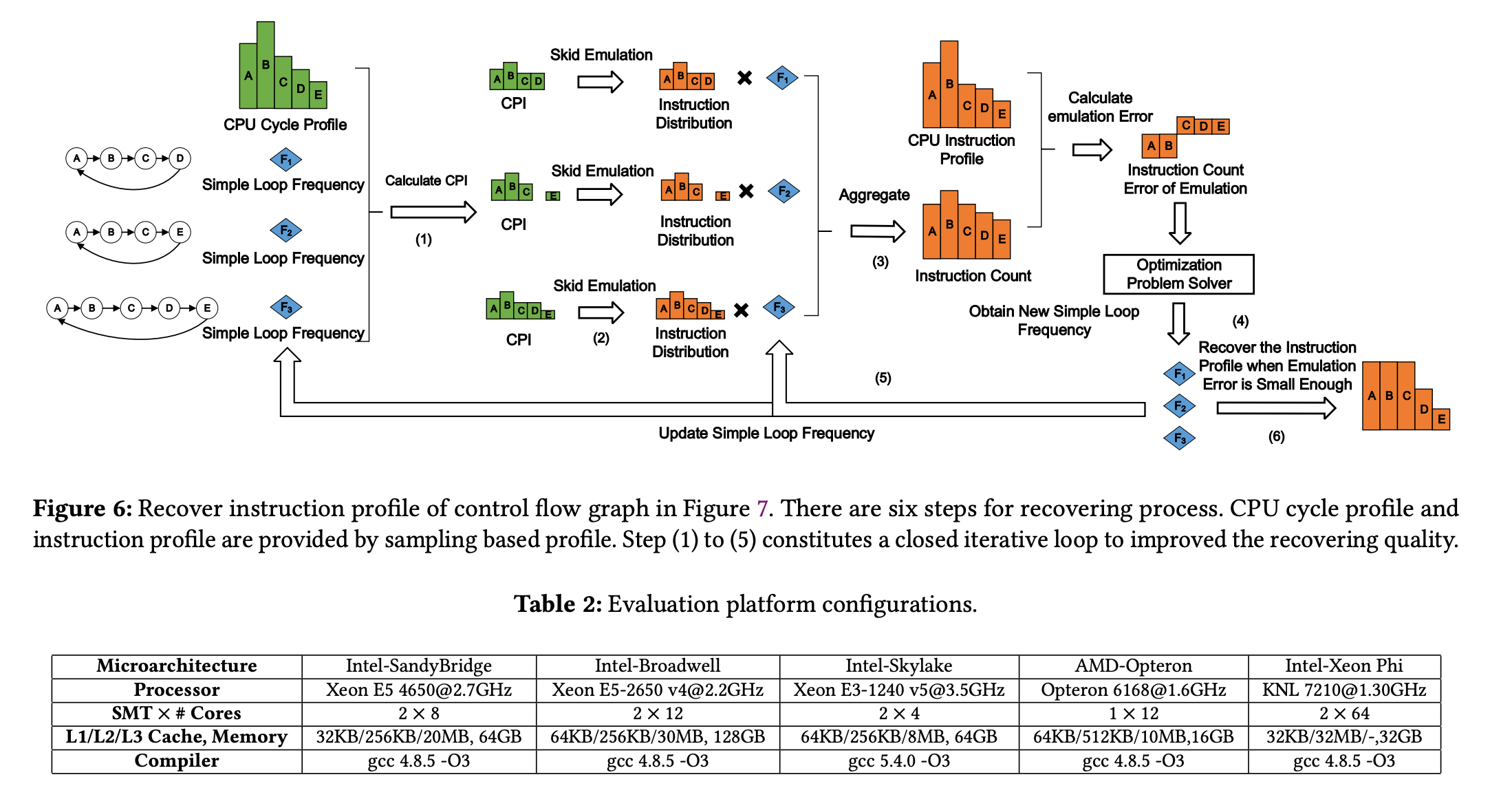
刚刚我们仅仅用简单的例子模拟了我们的程序情况。现在,我们需要将我们的修复技术推广到更加复杂的程序。这怎么做呢?文章分了3步:
第一段:分解程序,建立模型基础
我们将复杂程序的控制流图通过静态分析分解为多个“简单循环”的集合。每个简单循环是一个内部无分支的指令序列,其执行行为可以利用第三节建立的Skid模型进行精确模拟。这一步将无法直接处理的复杂程序,转化成了多个可被数学建模的基本单元。
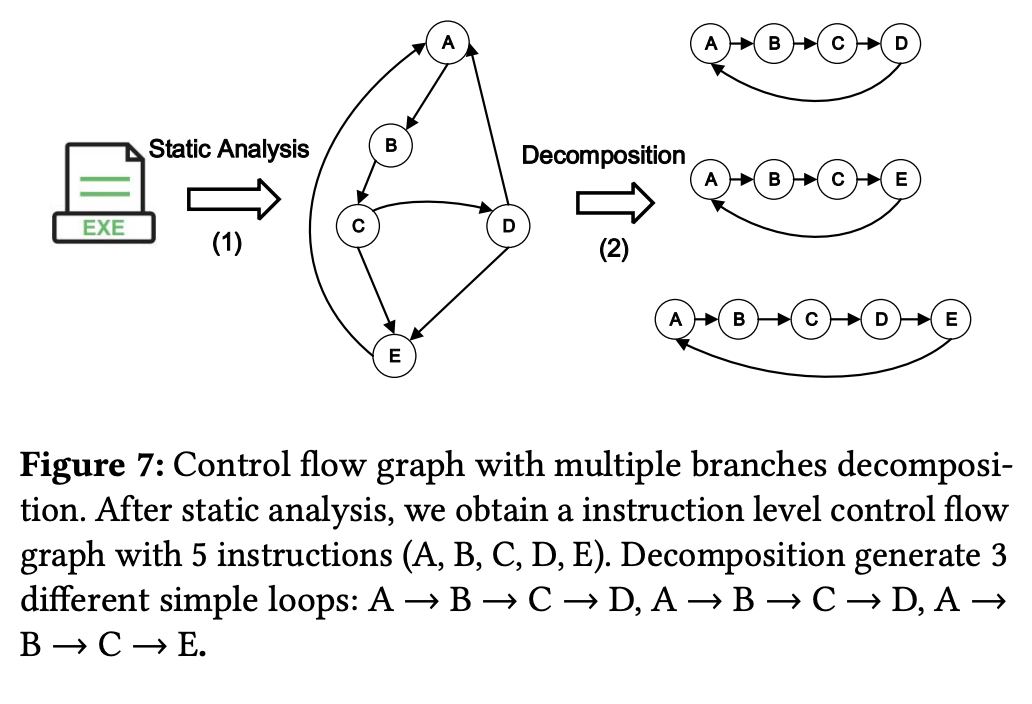
第二段:构建优化问题,反推真实频率
构建一个优化问题。算法以PMU采集到的不准确指令分布为目标,通过不断调整各简单循环的假设执行频率,并代入已知的Skid值来模拟生成指令分布。随后,我们将模拟结果与真实PMU数据进行比对,并利用优化算法(如Gibbs采样)反复迭代,寻找那一组能使两者差异最小的执行频率。这个过程实质上是反向求解,从而揭露出被Skid噪声掩盖的程序真实执行脉络。
第三段:重构档案,输出准确结果
在通过优化求解出各简单循环最可能的执行频率后,我们便跳出了Skid影响的怪圈。我们可以依据这些恢复的真实频率,结合程序的静态控制流图,直接像编译器一样逻辑推导出每条指令、每个函数被执行的实际次数,最终生成一份消除了Skid偏差的、准确的指令性能分析档案。
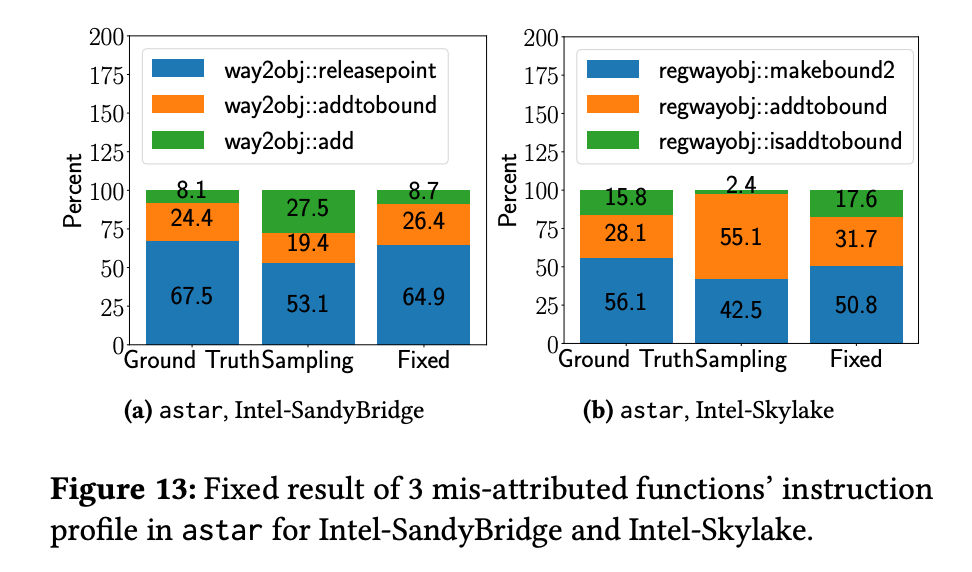
实验修复情况
PowerGraph Pagerank
SPEC CPU2006 astar