
Bigtable: The beginning of Big Data
- Big Data
- 2024-12-05
- 2327 Views
- 0 Comments
- 9929 Words
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.
GFS的出现虽然解决了海量数据的存储问题,但是还是存在一个问题就是如果我存放的数据是结构化的,对结构化数据的使用往往是希望如关系型数据库一样,进行复杂的数据操作的。但是GFS并没有支持基于特定属性(如行键、列名、时间戳)的高效查询、更新、聚合等操作。自然就需要大数据版本的关系型数据库,这就是分布式数据库。
在很多方面,Bigtable像是数据库,但相比于以往的系统,Bigtable提供了不一样的接口。它不支持完整的关系型数据模型。可以使用任意字符的行列名对数据进行索引,Bigtable将数据都视为未解释的字符串。
当然Bigtable也有缺点,一个是放弃了关系模型,不支持SQL;一个是放弃了跨行的事务,只支持单行的事务模型。
Bigtable的解决方法是:
- 将存储层搭建在GFS上,通过单Master调度多Tablets的形式,使得集群容易维护,伸缩性好
- 通过MenTable+SSTable的底层文件格式,解决高速随机读写的问题
- 通过Chubby分布式锁解决一致性的问题
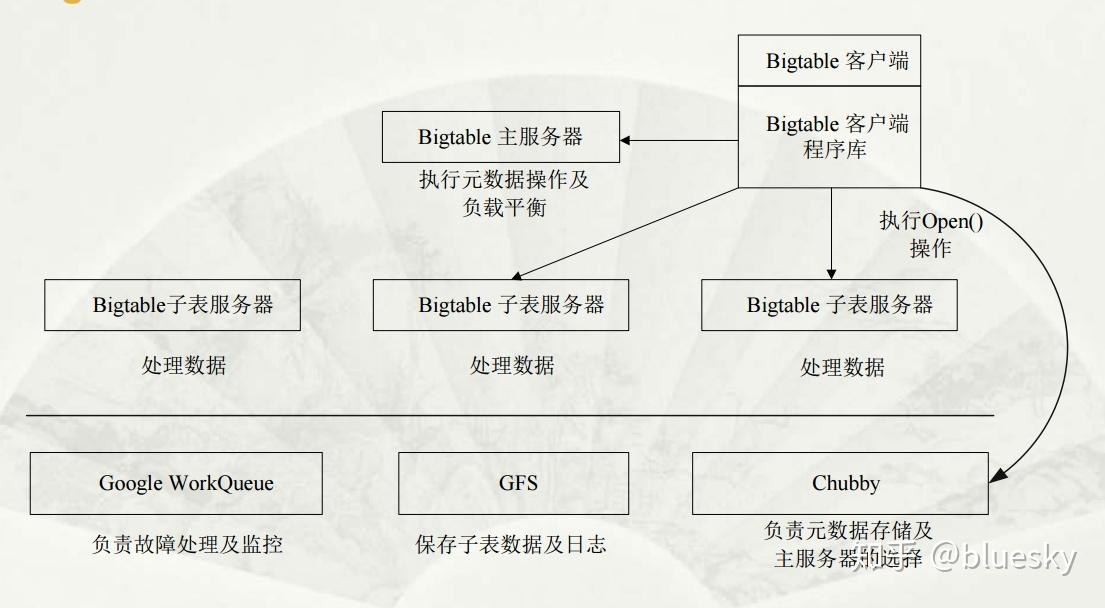
Bigtable包括四个组件:
- 负责存储数据的GFS
- 负责作为分布式锁和目录服务的Chubby
- 复杂提供在线服务的Tablet Server
- 复杂调度Tablet和调整负载的Master
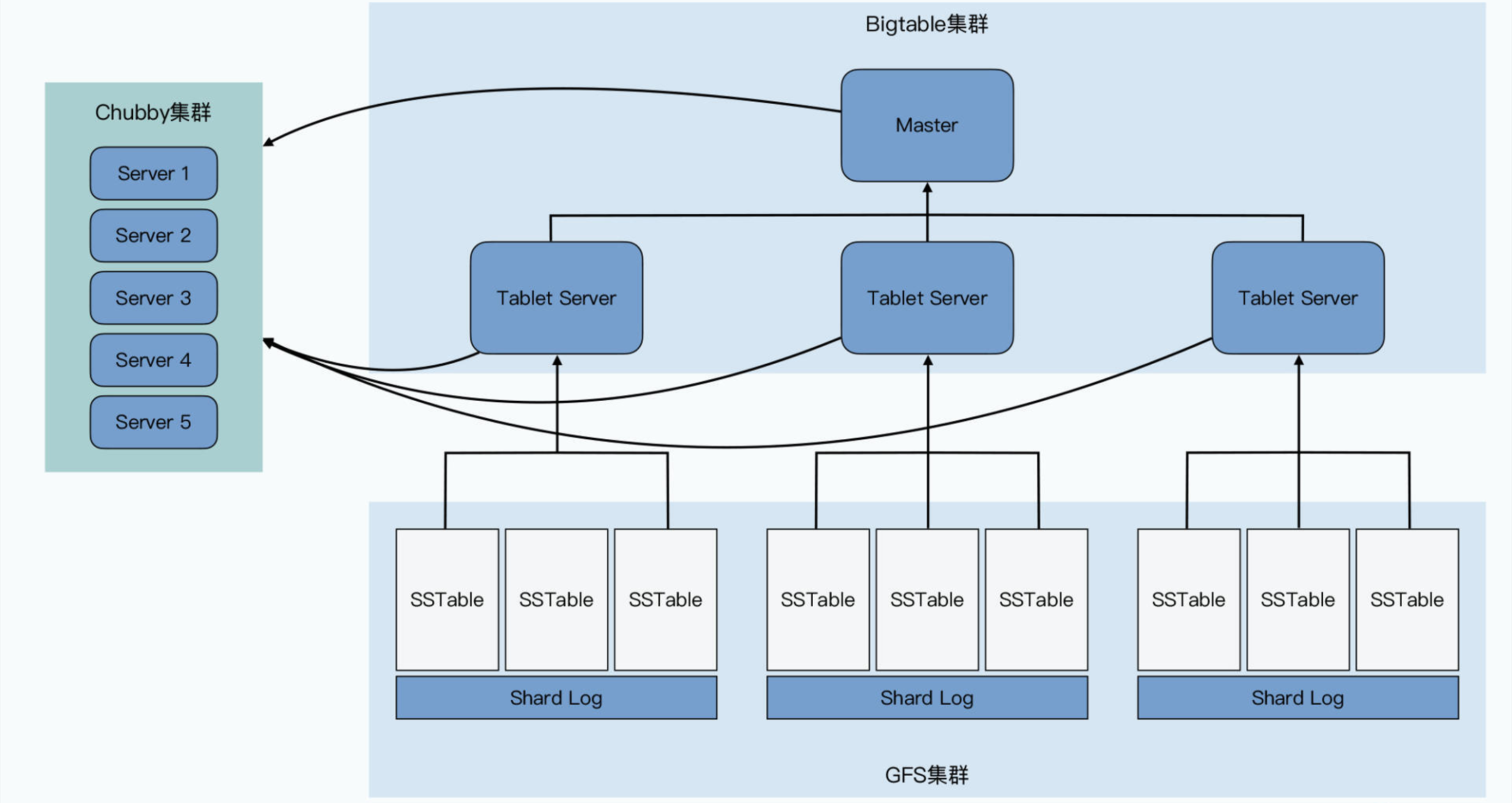
GFS回答的问题:
如何存储海量的数据?
如何高效地对海量数据进行读写?
要存海量数据自然要有良好的伸缩性,能轻松的进行节点扩展,能支持TB甚至PB级别的数据存储,要有高可靠性,要进行高性能的海量数据的读写其实就要能进行并发的读写。这些要求谁能满足?GFS就能满足,所以bigtable底层就是用GFS来存储数据的。
Map Reduce回答的问题:
如何处理海量的数据
big table要回答的问题:
能灵活进行数据操作?
- 需要存储的数据种类繁多,包括URL、网页内容、用户的个性化设置在内的数据都是Google需要经常处理的
- 需要存储的数据种类繁多海量的服务请求,Google运行着目前世界上最繁忙的系统,它每时每刻处理的客户服务请求数量是普通的系统根本无法承受的.
- 商用数据库无法满足需求,一方面现有商用数据库的设计着眼点在于其通用性。另一方面对于底层系统的完全掌控会给后期的系统维护、升级带来极大的便利
这是传统的关系型数据库不行的地方,变成NoSQL
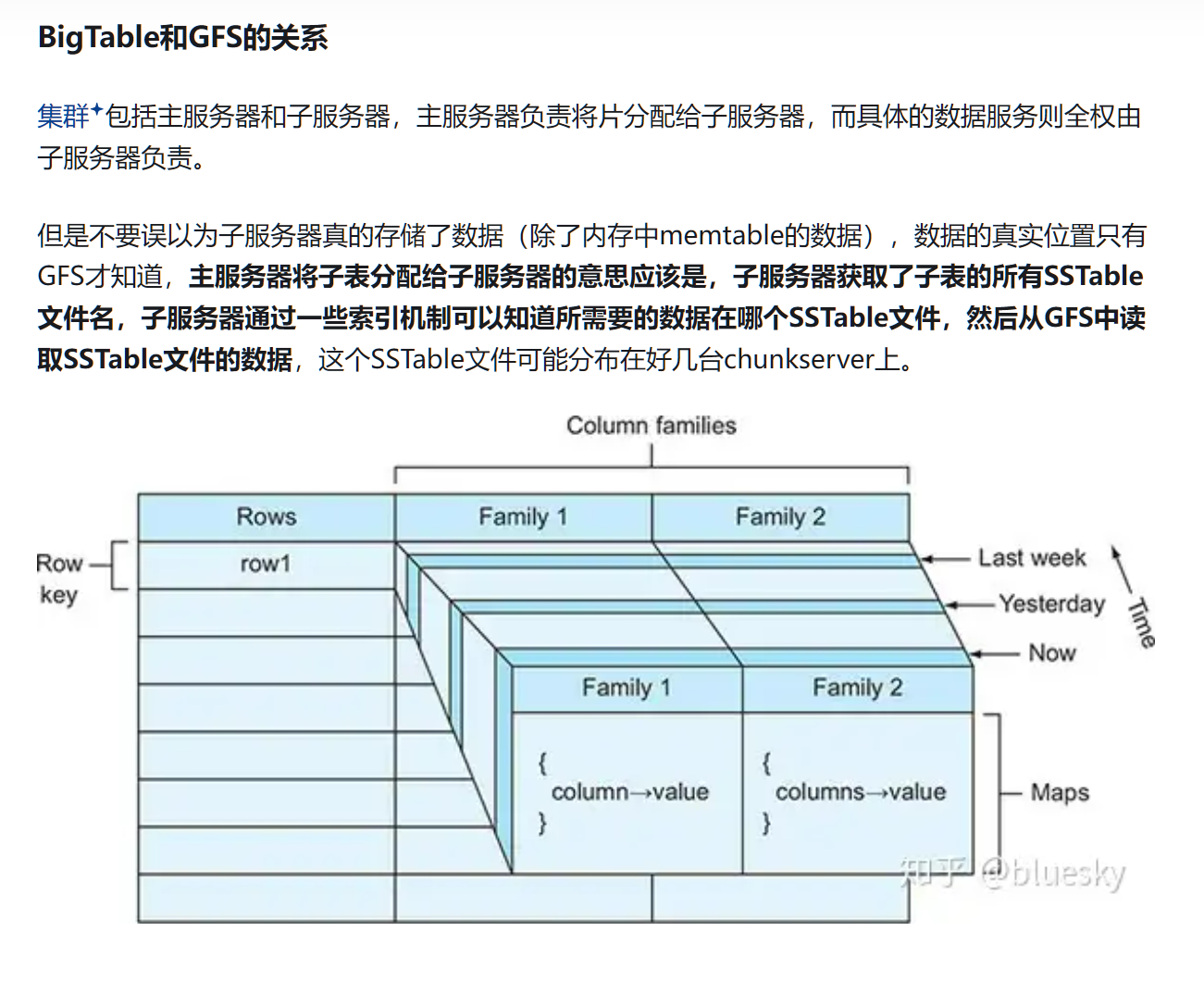
Cell
bigtable采用一种基于行键(row key)、列族(column family)和时间戳(timestamp)的多维数据模型,允许用户以高效、灵活的方式组织和访问数据。

行是固定的,列是动态的,还可以有时间上的区别
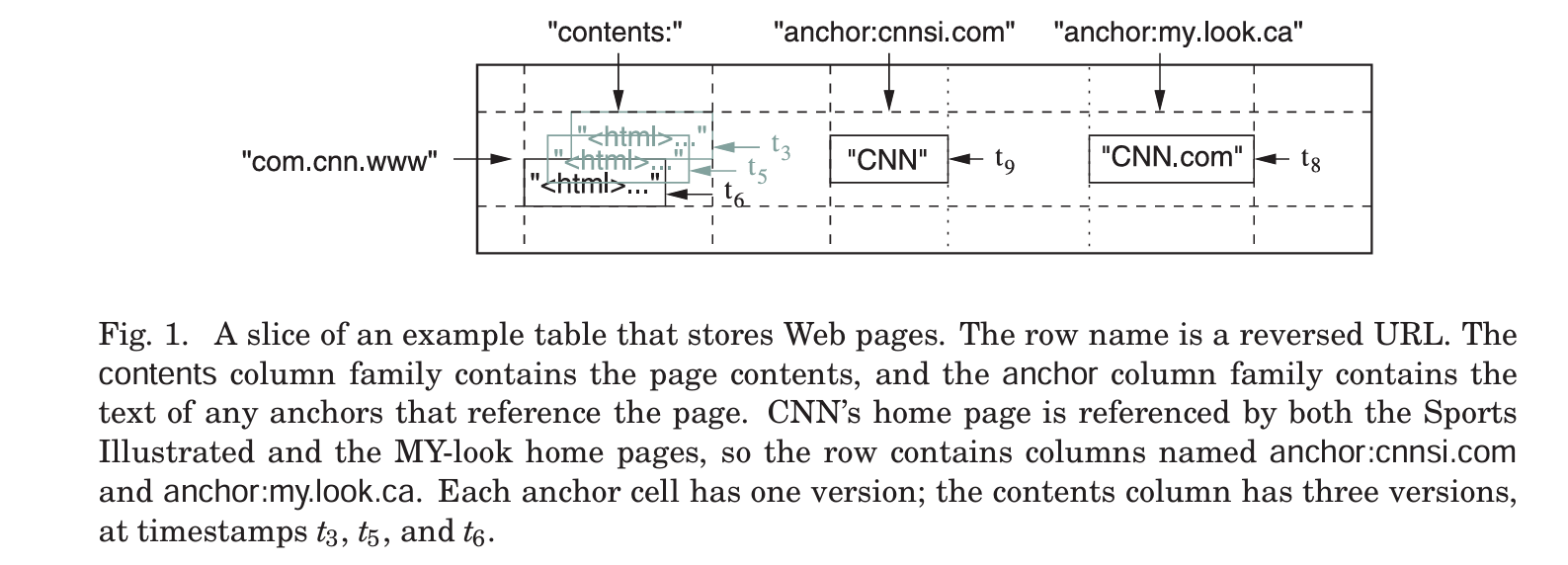
com.cnn.www 网站,唯一
contents: 不同时间内这个网站的内容
anchor:cnnsi.com: cnnsi.com链接这个网站
anchor:my.look.ca: my.look.ca链接这个网站
API
由于数据是分布式存储的,所以其实bigtable还是没办法办到像SQL一样灵活的对数据进行操作,其只能尽力的在GFS之上封装出一套完整的增删改查操作。bigtable支持以下类型的API:
建表、删表
单行数据的增删查,以及用删除和增加组合出来的修改效果,只对单行数据的增删具有ACID特性。
范围查询

BigTable 是一个稀疏的、分布式的、可持久化的多维有序 map。
map 通过 rowKey,columnKey 和时间戳进行索引,map 中的每个值都是一个连续的字节数组。
注:rowKey 是记录的主键,唯一标识一行记录
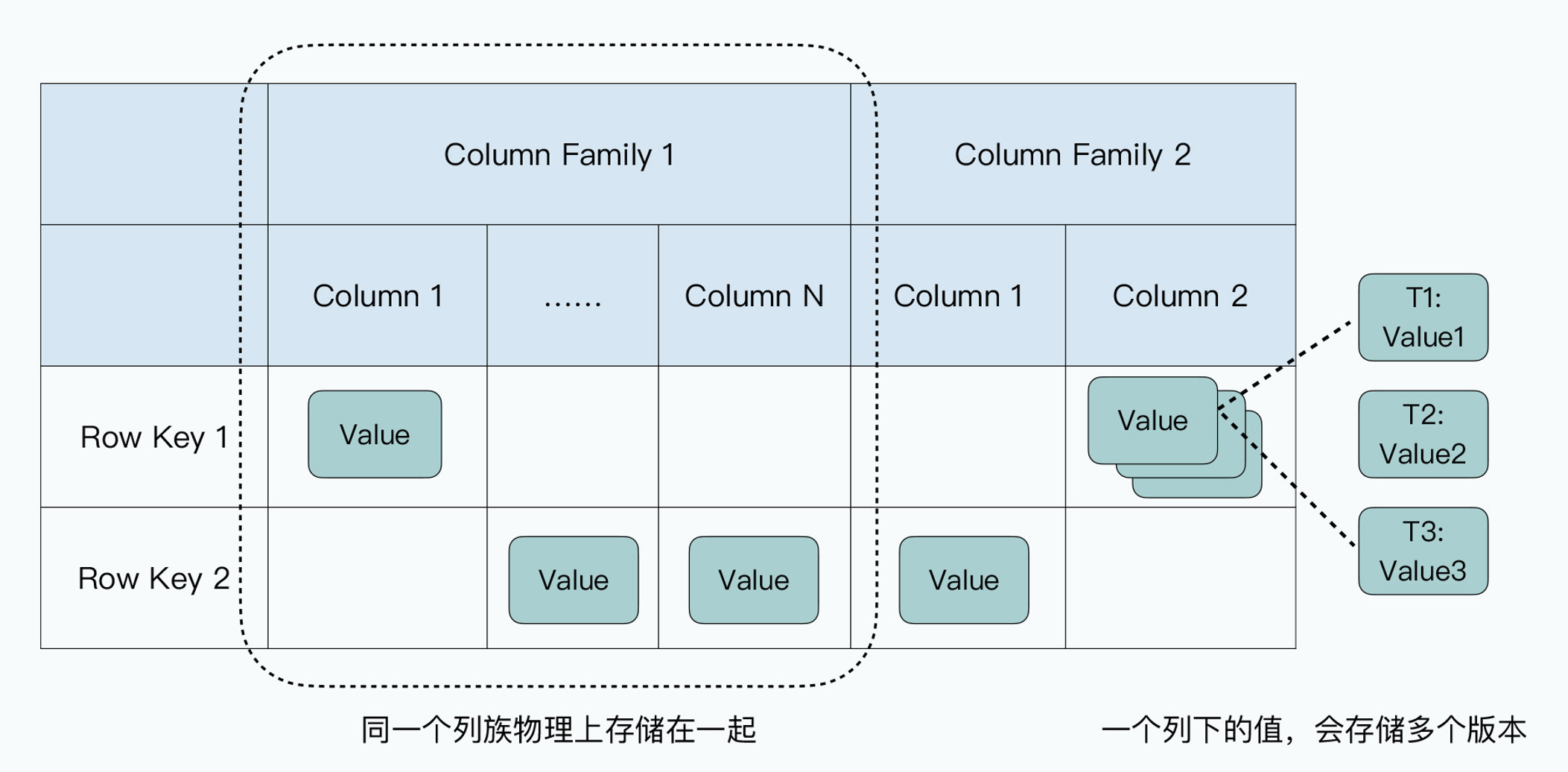
如果我的主页简介改变了,就只需要新加新的简介的那一个KV对,那对新的KV对生成新的时间序列即可。
使用chubby:高可用、持久的分布式锁服务
一个 Chubby 服务由 5 个活跃副本(active replicas)组成,其中一个会被选举为 master,并负责处理请求。只有大多数副本都活着,并且互相之间可以通信时,这个服务才 算活着(live)。
在遇到故障时,Chubby 使用 Paxos 算法 [9, 23] 保证副本之间的一致性。
Chubby 提供了一个包含目录和小文件的命名空间(namespace),每个目录或文件都 可以作为一个锁,读或写一个文件是原子的。
Chubby 客户端库维护了一份这些文件的一致性缓存(consistent caching)。每个 Chubby 客户端都会和 Chubby 服务维持一个 session。当一个客户端的租约(lease)到期 并且无法续约(renew)时,这个 session 就失效了。session 失效后会失去它之前的锁 和打开的文件句柄(handle)。Chubby 客户端还可以在 Chubby 文件和目录上注册回调 函数,当文件/目录有变化或者 session 过期时,就会收到通知。
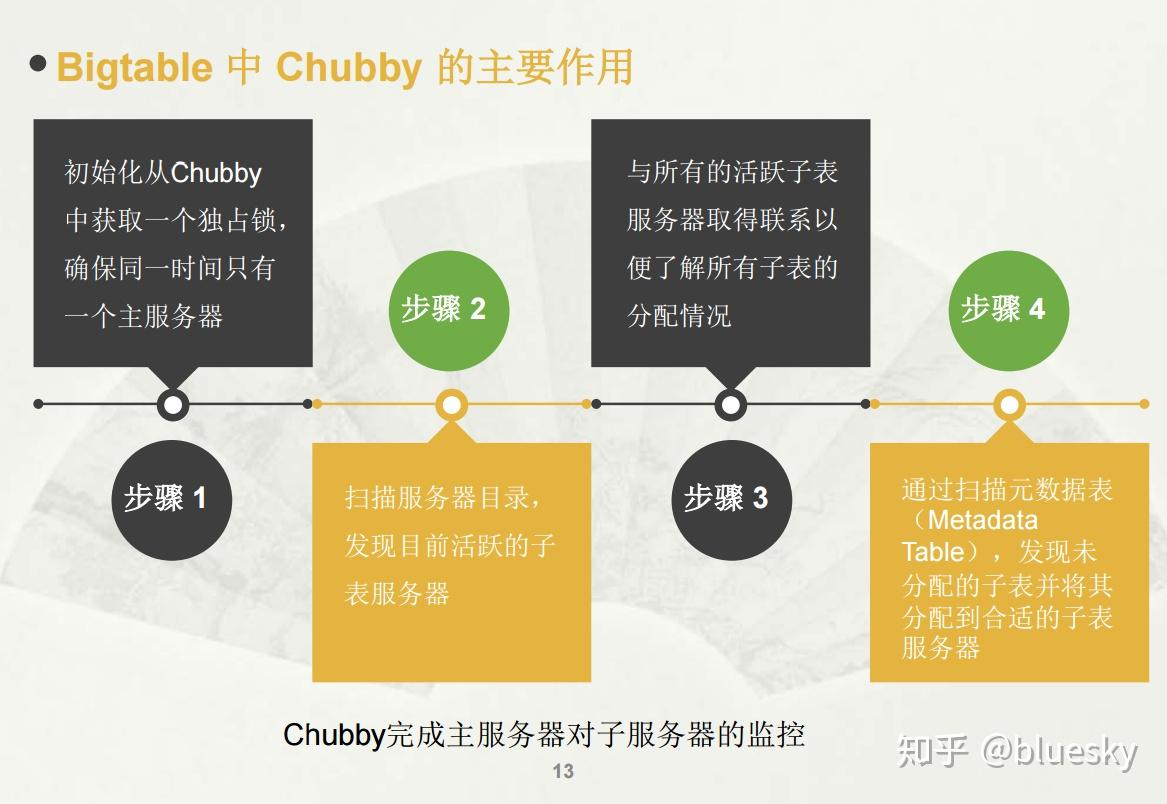
Bigtable 使用 Chubby 完成很多不同类型的工作:
- 保证任何时间最多只有一个 active master
- 存储 Bigtable 数据的 bootstrap location(见 5.1)
- tablet 服务发现和服务终止清理工作(见 5.2)
- 存储 Bigtable schema 信息(每个 table 的 column family 信息)
- 存储访问控制列表
存储
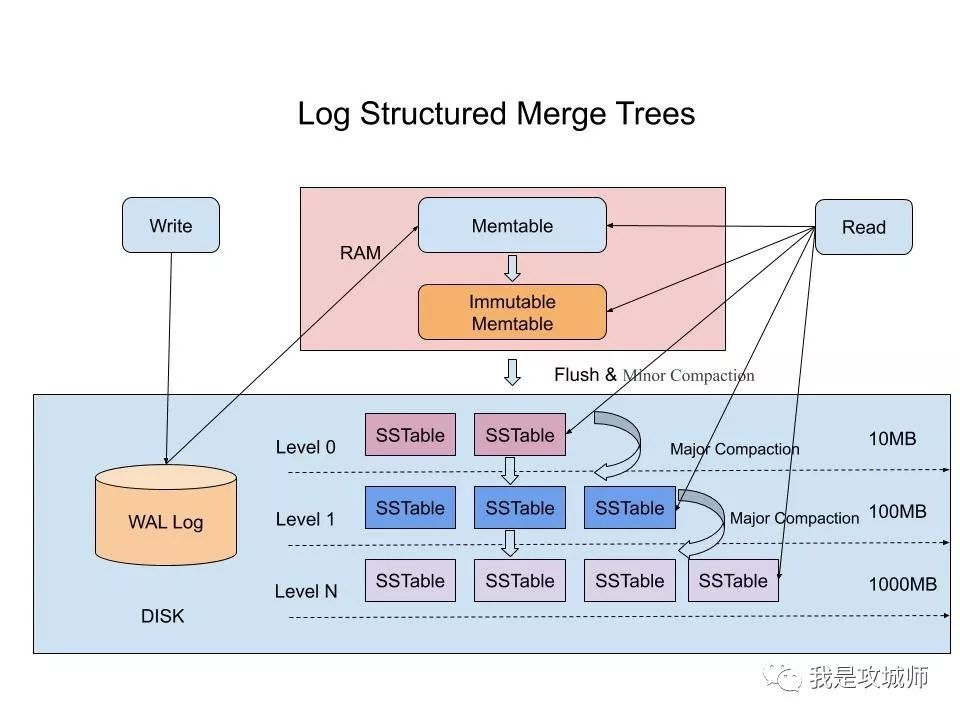
一张大表肯定是不能存在一个服务器上的,而是被分成多份存在多个服务器上,一份就是一个逻辑单位——tablet。bigtable架构中最核心的概念是tablet。存放tablet的节点在bigtable体系中叫做tablet server,一个tablet server中存放多个tablet。bigtable在最底层把数据按照key进行排列后,进行分区,一个分区就是一个tablet,而一个tablet就是GFS中的一个文件。
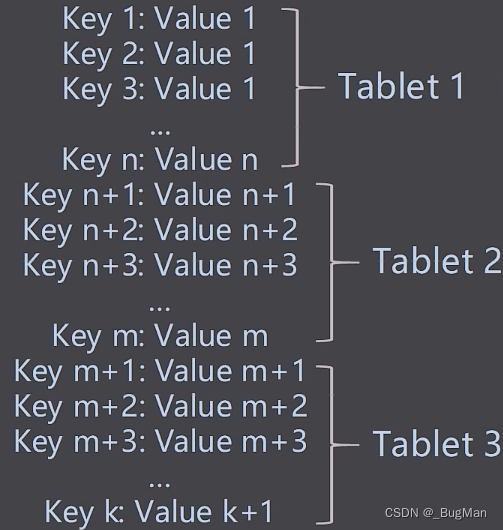
tablet只是一个逻辑概念,指代特定范围内的数据行。真正干活儿的是memtable和sstable以及下面的GFS。memtable和sstable可以理解为索引,一个tablet对应着一套memtable和sstable。由于大数据中数据是海量的,所以将索引结构存在磁盘,每次对数据的更新(写入、删除)都要去更新磁盘,肯定是扛不住的。所以将索引放在内存中才是明智的,memtable是缓存,可以理解为就是内存中的索引,一个tablet对应着一个memtable,其中记录着当前节点的tablet中的所有数据(key值+数据指针)。为了容错和可靠,memtable每隔一段时间或者到了一定的阈值后会落磁盘进行持久化,持久化为SSTable,一个tablet存在多个SSTable,这样设计的目的是省去了新老sstable合并带来的额外磁盘IO拉低吞吐量,也可以起到数据版本记录的目的。
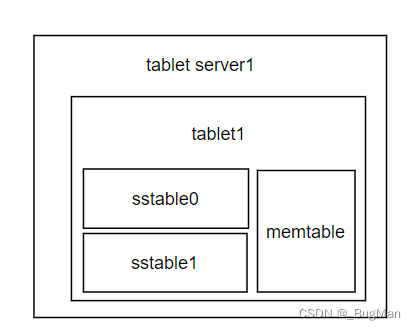
memtable和sstable中存放的什么内容:数据的key+数据存在 GFS 的哪个 DataNode 上
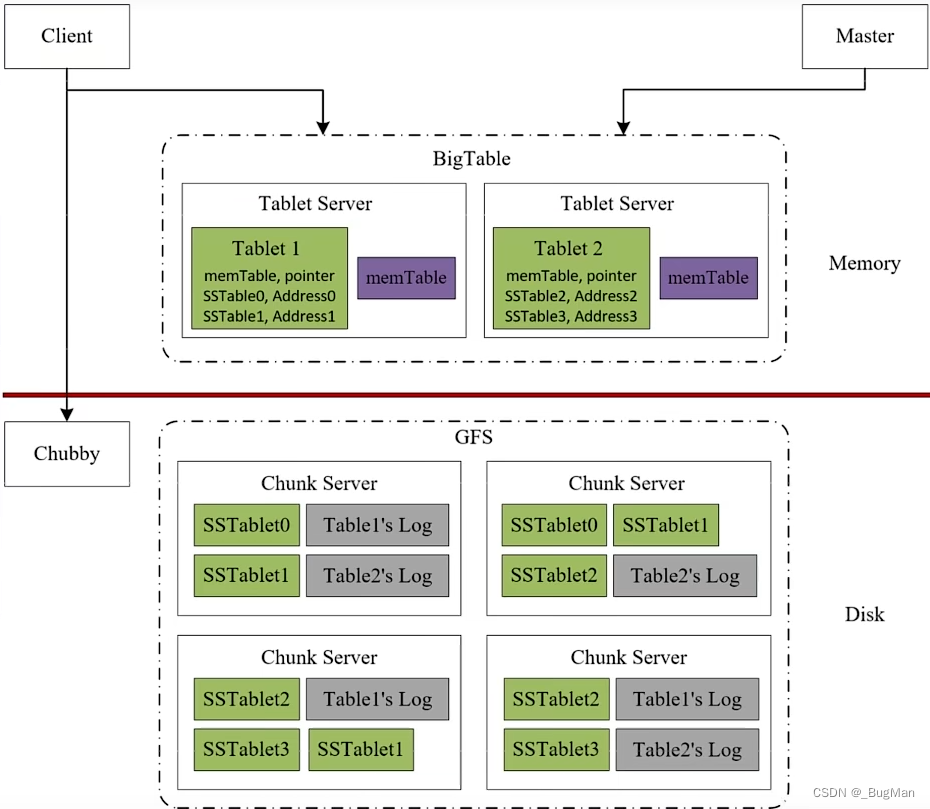
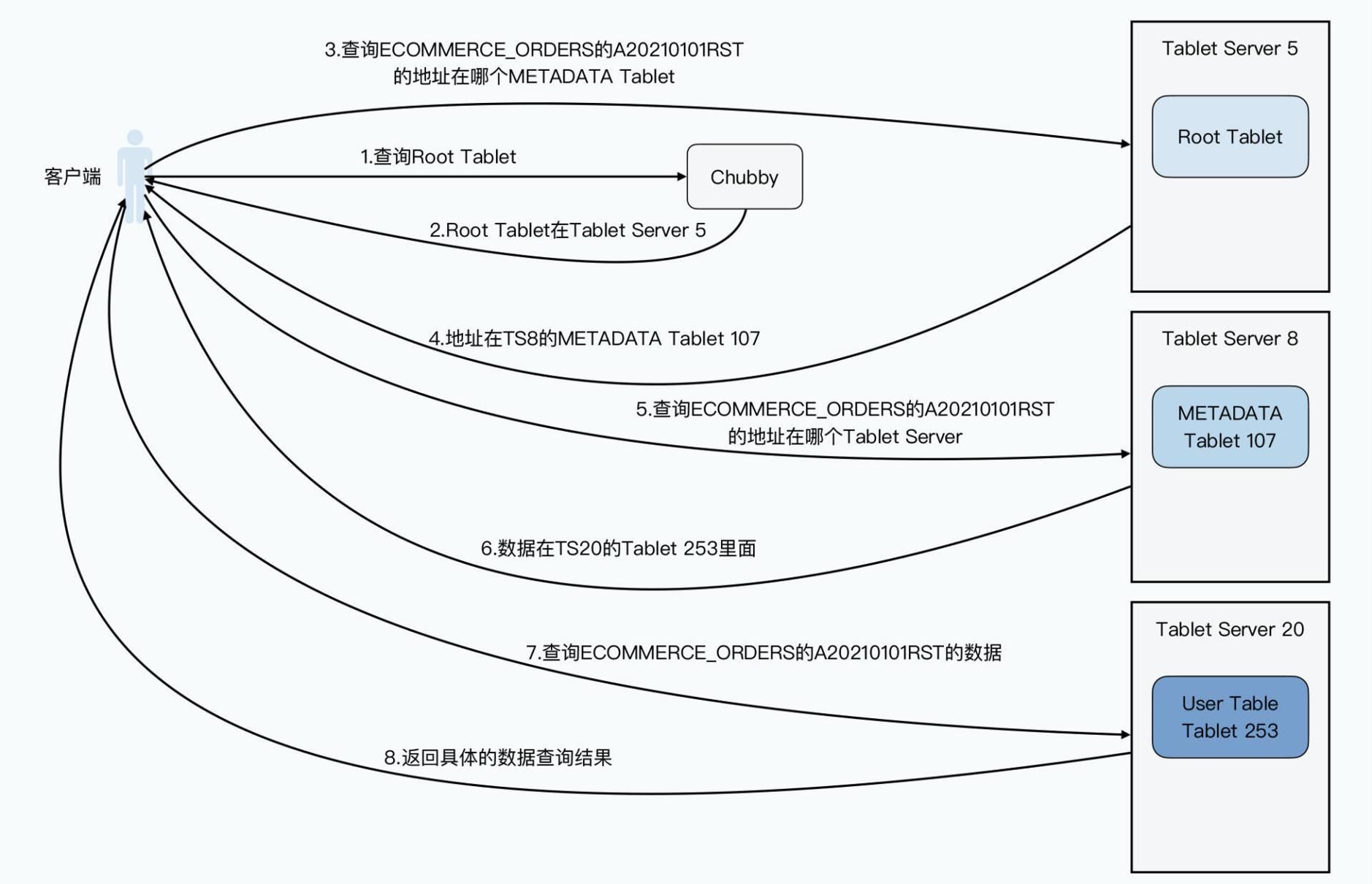
各个tablet server各自管理着一部分tablet信息,所以还需要一个全局的协调者(master节点)来负责记录下全局的:
哪些key在哪个tablet中,以及哪些tablet在哪些节点上。
所以综上所述整个bigtable的架构图如下:
Bigtable relies on a highly-available and persistent distributed lock service called Chubby [8]. A Chubby service consists of five active replicas, one of which is elected to be the master and actively serve requests. The service is live when a majority of the replicas are running and can communicate with each other. Chubby uses the Paxos algorithm [9, 23] to keep its replicas consistent in the face of failure. Chubby provides a namespace that consists of directories and small files. Each directory or f ile can be used as a lock, and reads and writes to a file are atomic. The Chubby client library provides consis tent caching of Chubby files. Each Chubby client main tains a session with a Chubby service. A client’s session expires if it is unable to renew its session lease within the lease expiration time. When a client’s session expires, it loses any locks and open handles. Chubby clients can also register callbacks on Chubby files and directories for notification of changes or session expiration. Bigtable uses Chubby for a variety of tasks: to ensure that there is at most one active master at any time; to store the bootstrap location of Bigtable data (see Sec tion 5.1); to discover tablet servers and finalize tablet server deaths (see Section 5.2); to store Bigtable schema information (the column family information for each ta ble); and to store access control lists. If Chubby becomes unavailable for an extended period of time, Bigtable be comes unavailable. We recently measured this effect in 14 Bigtable clusters spanning 11 Chubby instances. The average percentage of Bigtable server hours during which somedata stored in Bigtable was not available due to Chubby unavailability (caused by either Chubby out ages or network issues) was 0.0047%. The percentage for the single cluster that was most affected by Chubby unavailability was 0.0326%
为什么要设计出tablet的概念喃?
这是因为在关系型数据库中数据量是没那么大的,在管理粒度上细到单个数据上是没什么问题的。因为当我们想用树形结构来进行查找上的性能优化的时候(索引)倒是没什么问题(B+树完全扛得住),但是在大数据系统中动辄上TB和PB的数据量级,仍然细到单个数据上这棵树形结构该有多深?多大?所以是扛不住的,最佳的方式当然是先用tablet来“分块”一下,树形结构直接管理到tablet层面即可,tablet内部再来进行自我的数据组织(内部再维护一种树形结构),这样就扛得住了,树也不会太深。
————————————————
原文链接:https://blog.csdn.net/Joker_ZJN/article/details/137988452
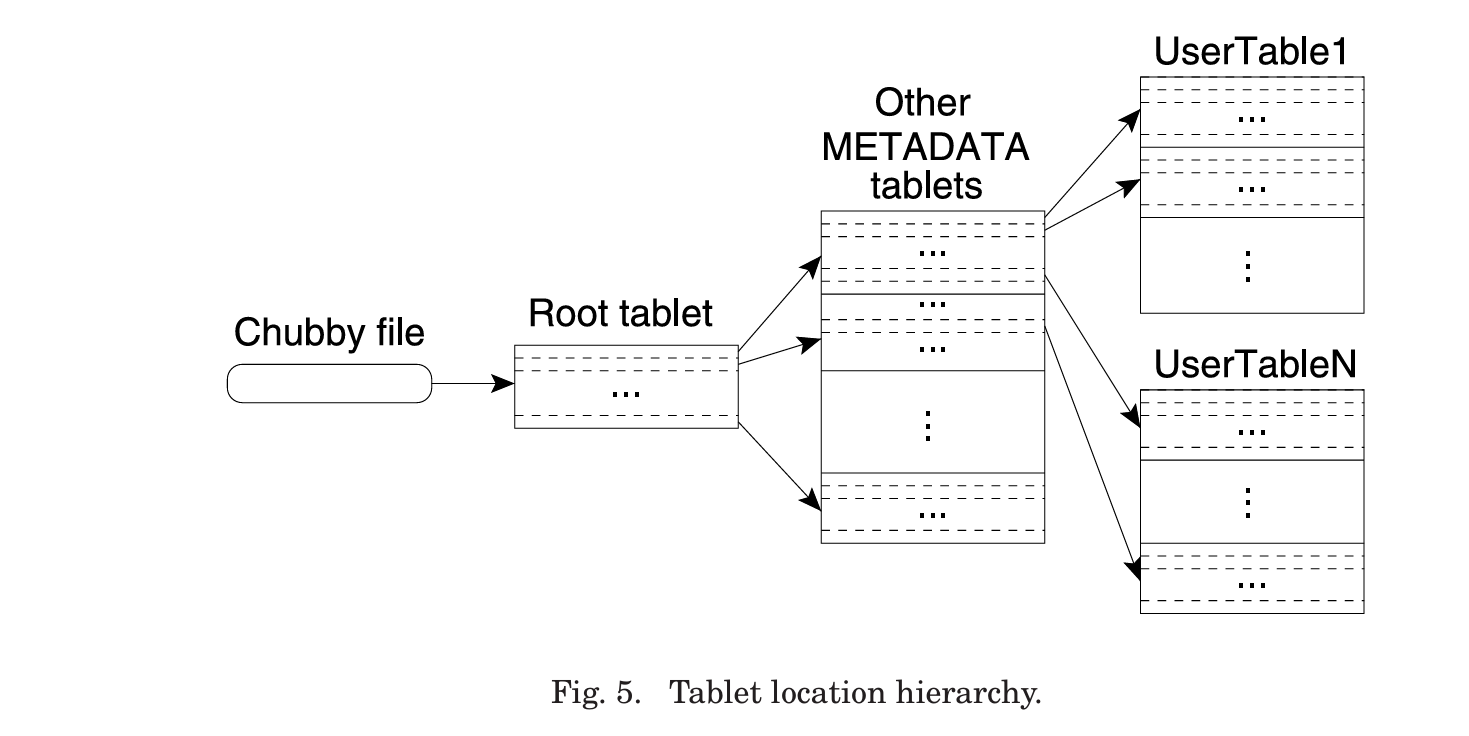
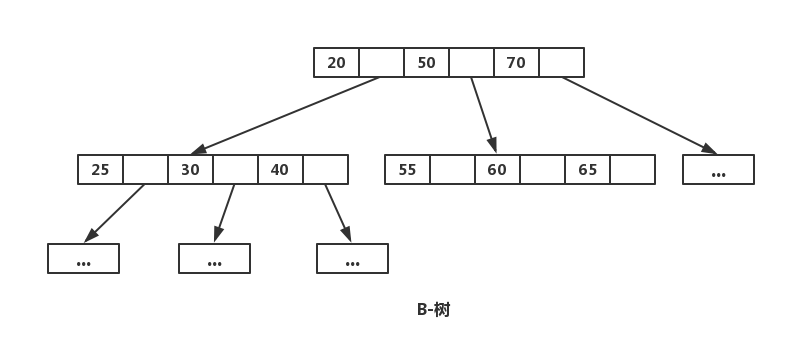
We use a three-level hierarchy analogous to that of a B+-tree [Comer 1979] to store tablet location information (Figure 5).
使用Chubby 来维持一个table的索引,就向B树一样
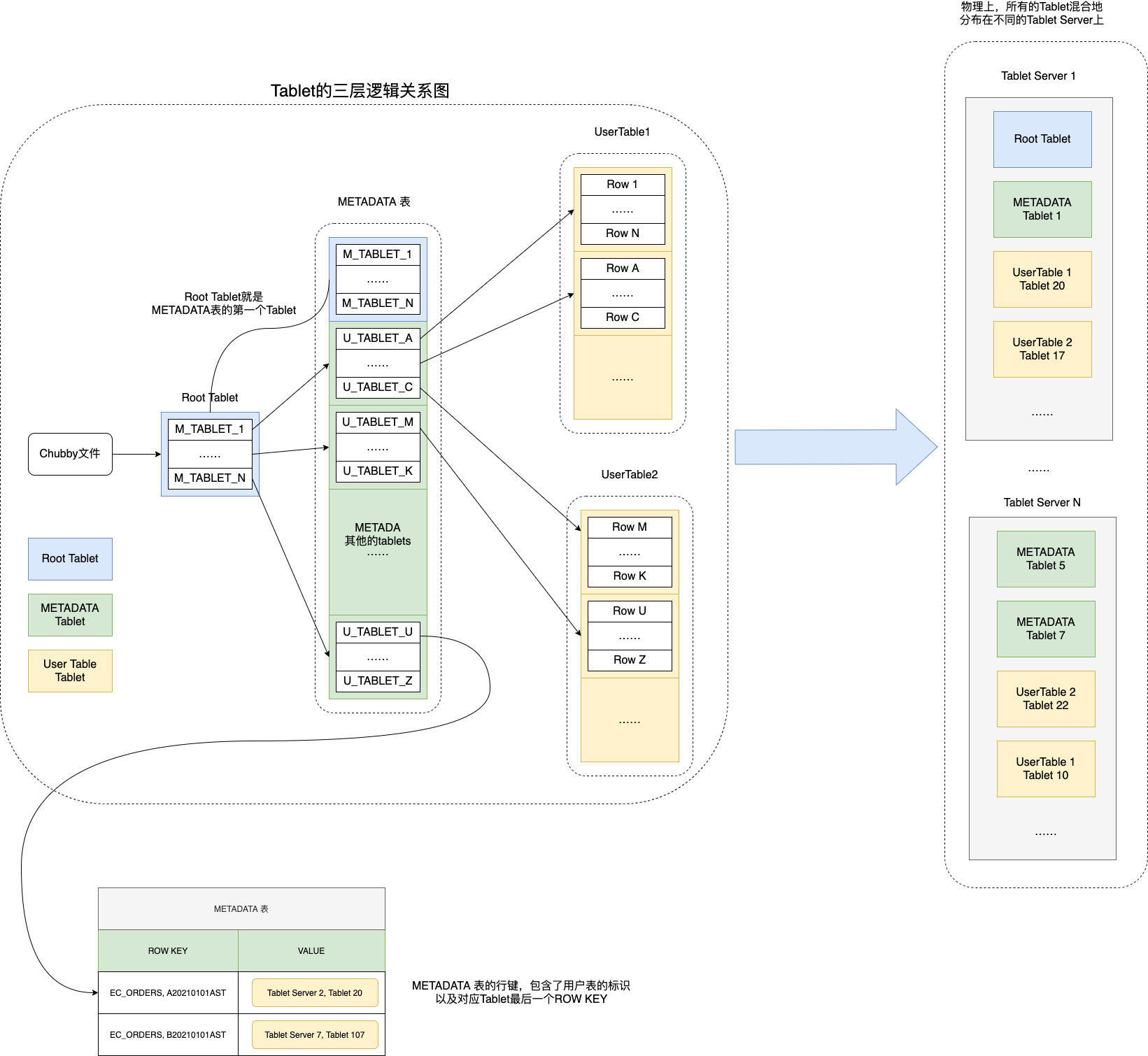
- 第一级:Chubby 中的一个文件
- 第二级:METADATA tables(第一个
METADATAtable 比较特殊,所以在图中单独画 出,但它其实和其他METADATAtable 都属于第二级) - 第三级:user tablets
METADATA 是一个特殊的 tablet,其中的第一个 tablet 称为 root tablet。root tablet 和 METADATA 内其他 tablet 不同之处在于:它永远不会分裂(split),这 样就可以保证 tablet location 层级不会超过三层。
tablet只是一个逻辑概念,指代特定范围内的数据行。真正干活儿的是memtable和sstable以及下面的GFS。memtable和sstable可以理解为索引,一个tablet对应着一套memtable和sstable。由于大数据中数据是海量的,所以将索引结构存在磁盘,每次对数据的更新(写入、删除)都要去更新磁盘,肯定是扛不住的。所以将索引放在内存中才是明智的,memtable是缓存,可以理解为就是内存中的索引,一个tablet对应着一个memtable,其中记录着当前节点的tablet中的所有数据(key值+数据指针)。为了容错和可靠,memtable每隔一段时间或者到了一定的阈值后会落磁盘进行持久化,持久化为SSTable,一个tablet存在多个SSTable,这样设计的目的是省去了新老sstable合并带来的额外磁盘IO拉低吞吐量,也可以起到数据版本记录的目的
————————————————
原文链接:https://blog.csdn.net/Joker_ZJN/article/details/137988452
SSTable && tablet
在 Bigtable 中,tablet 是一个关键的存储单位,它负责在底层存储和管理数据。Bigtable 将数据划分为多个 tablet,每个 tablet 管理一部分数据,并且每个 tablet 可以独立存储、加载和迁移。以下是有关 Bigtable 中 tablet 存储的详细信息:
1. Tablet 的定义
- Tablet:是 Bigtable 的数据分片单位,每个 tablet 负责管理一定范围的行。每个 tablet 由一个连续的行键范围定义。这个范围可以是表中的所有数据的一个子集。
- Tablet Server:是处理和管理 tablets 的服务器,负责处理对该 tablet 的读取和写入请求。
2. Tablet 的存储结构
-
数据存储:
- SSTable(Sorted String Table):tablet 内部的数据主要存储为 SSTables,这是一种高效的排序表格式。SSTable 是不可变的文件格式,用于存储数据块,并且提供了高效的查找和检索机制。
- MemTable:在数据写入时,首先会被写入到 MemTable 中,这是一个内存中的数据结构。MemTable 会在达到一定大小后,刷新到磁盘上,形成一个新的 SSTable 文件。(Cache)
-
Log(Write-Ahead Log, WAL):为了确保数据的持久性,所有的写操作都会首先记录到写前日志中。这个日志确保即使发生故障,也能通过重放日志来恢复未写入到 MemTable 的数据。
3. Tablet 的管理与分配
- 分区:Bigtable 将数据表的行键范围划分为多个 tablets,这些 tablets 负责处理和存储该范围内的数据。每个 tablet 对应一个文件或一组文件。
- 动态调整:随着数据量的增加或减少,tablet 会被动态地分裂或合并。例如,如果一个 tablet 的数据量增长到一定程度,它会被分裂成两个较小的 tablets,以保持负载均衡。
- 负载均衡:tablet 会在多个 tablet servers 之间进行平衡,以确保负载均匀分布。这有助于提高系统的可伸缩性和性能。
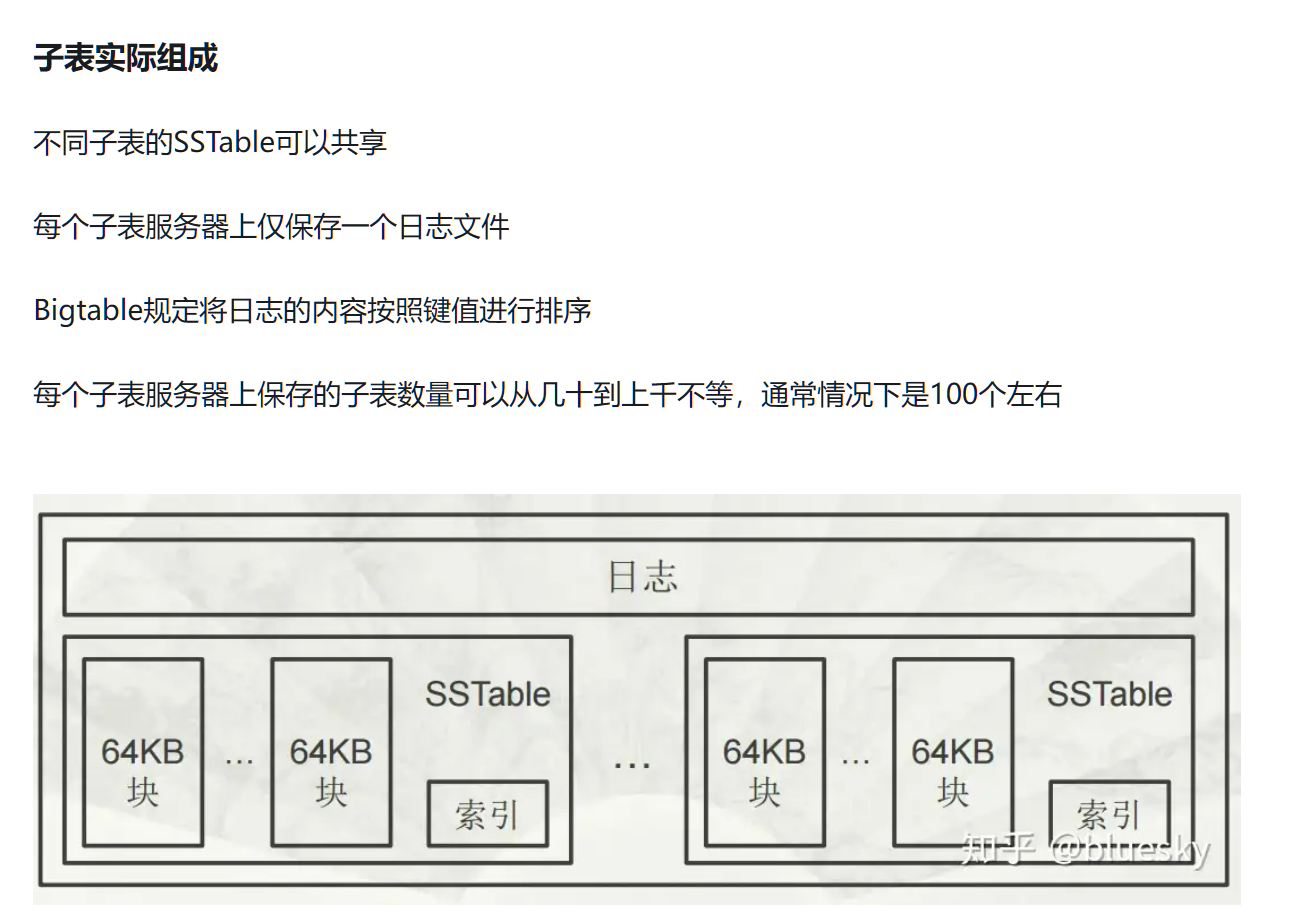
Bigtable采用动态区间分区,通过自动去split的方式动态分区。 好比是往箱子里放书,按照书名的字母顺序,一旦箱子装满,就中间一分为二,将下面一半放到一个新的空箱子里去。 如果两个相邻的箱子都很空,就可以将其合并。
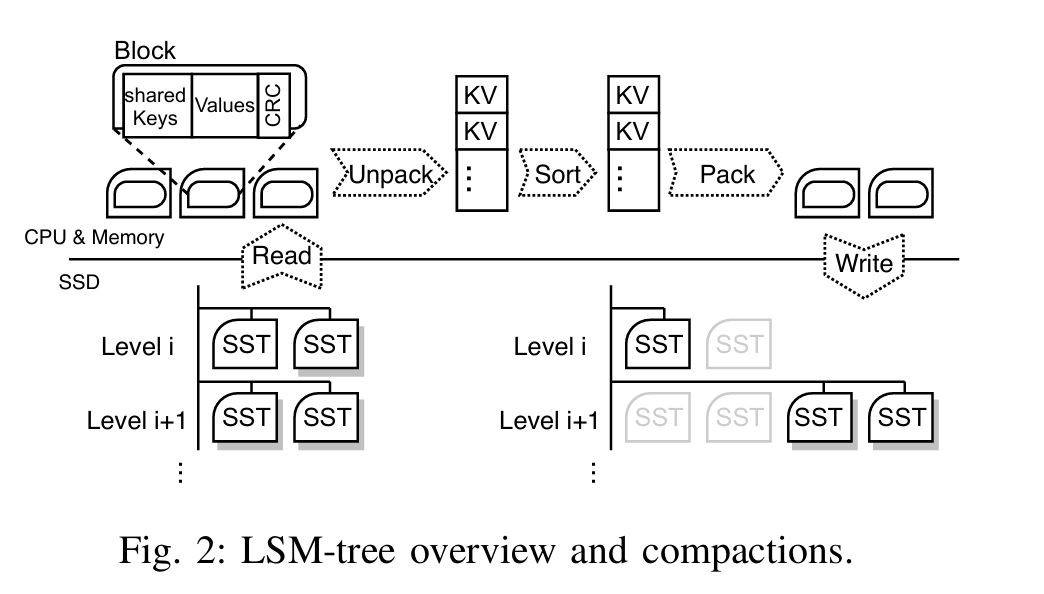
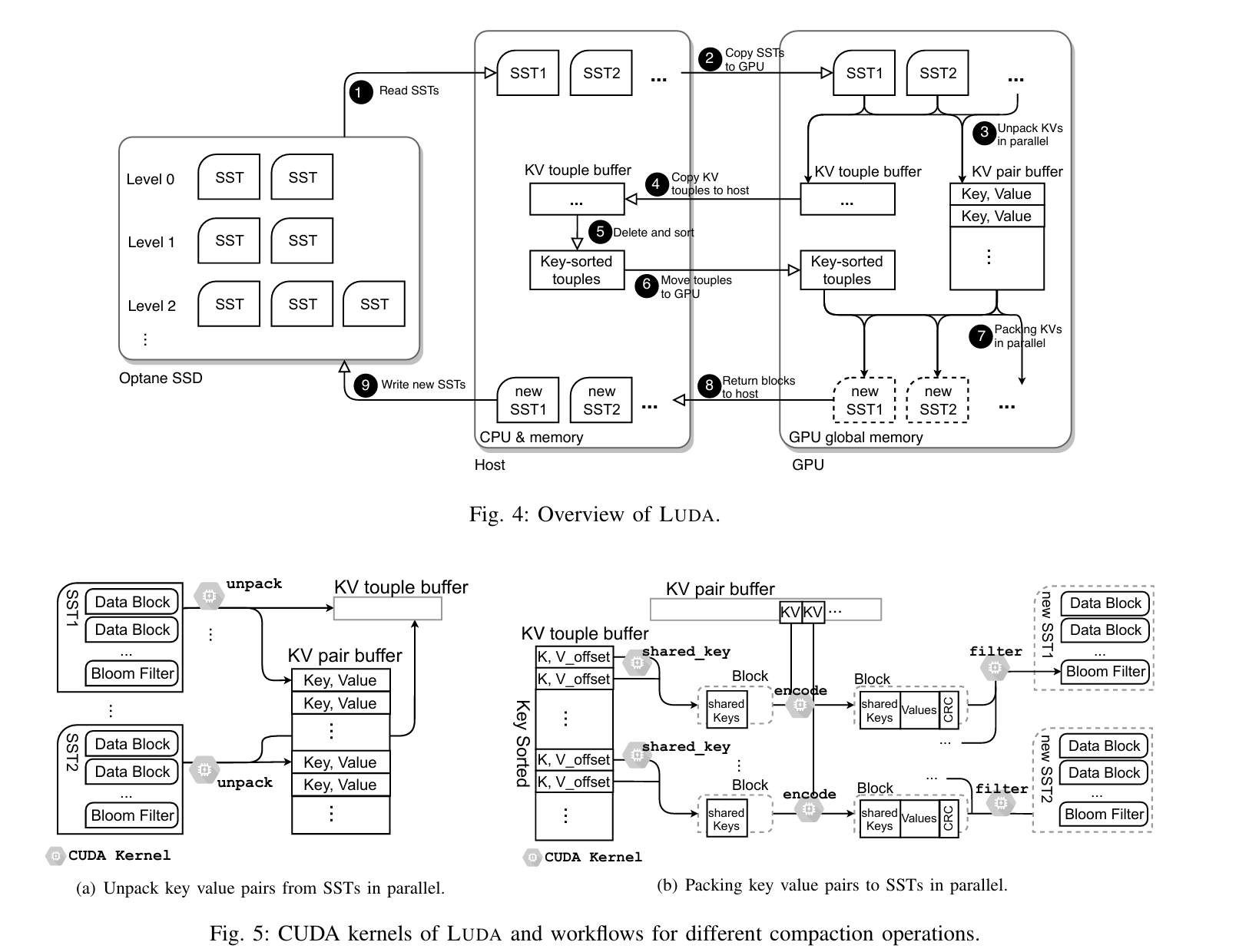

华中科技大学计算机学院;武汉光电国家实验室
采用GPU来boost LSM KV compactions
4. 数据检索与写入
- 读取操作:当查询数据时,Bigtable 首先检查 MemTable,然后查找 SSTables。如果需要,也会在 WAL 中查找最近的更新。
- 写入操作:写入数据时,数据首先进入 MemTable,并记录到 WAL。当 MemTable 满时,它会被转储为一个新的 SSTable 文件。
Bigtable的写入数据的过程:
- tablet server先做数据验证,以及权限验证
- 如果合法,就以追加写的形式顺序写到GFS
- 写入成功后还会写到一张内存表MenTable中
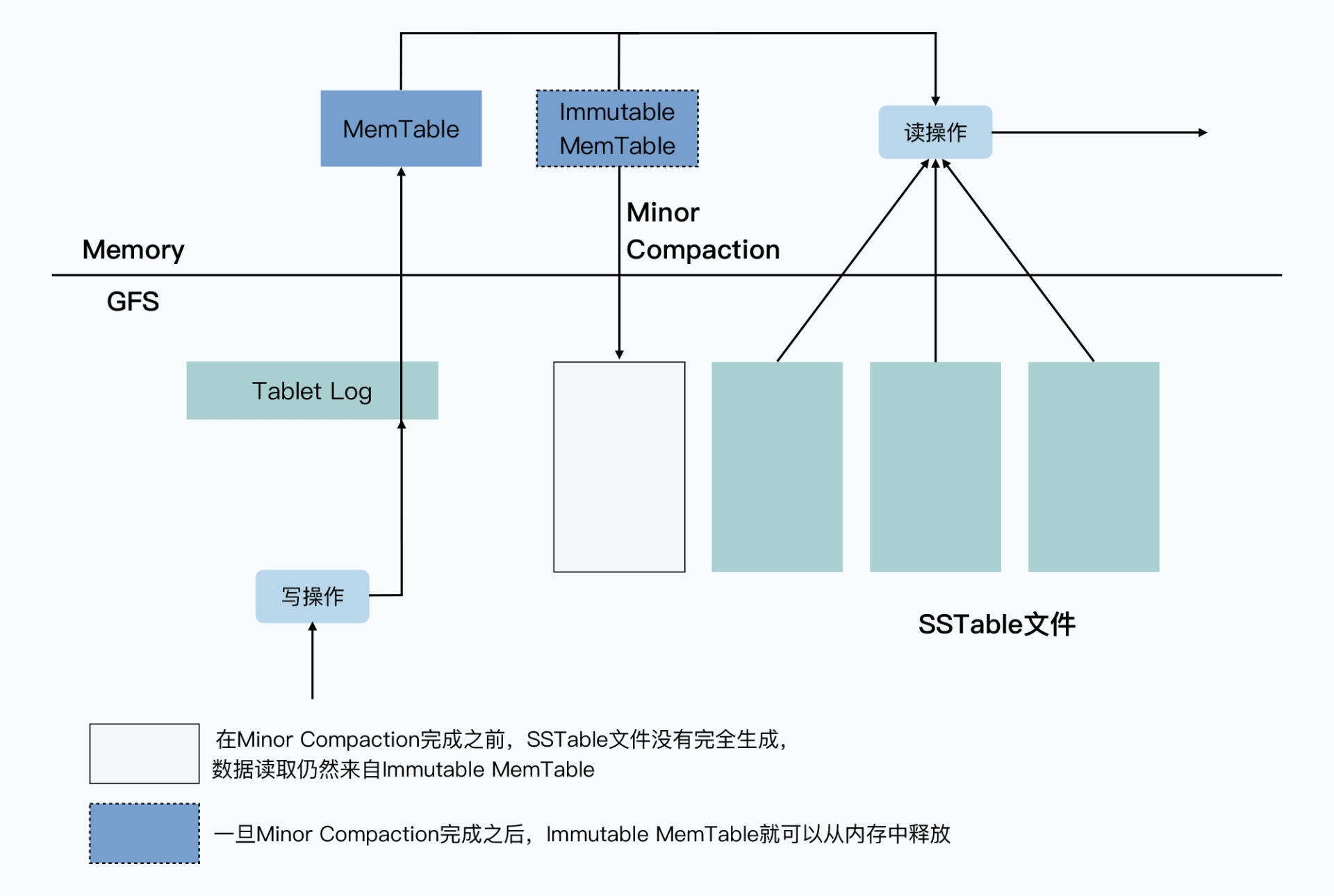
- 写入的数据快要超过阈值时,会将内存的MemTable冻结,创建一个新的MemTable,被冻结的MemTable会被转换为SSTable写入到GFS,然后从内存中释放掉。
Major Compaction机制,对SSTable进行合并,把数据压实在一起,比如只留下时间戳最近的三个版本的数据。 读取数据的时候,读取的是MemTable和SSTable的合并在一起的视图。 也就是说并没有直接的修改和删除操作,一旦写入就是不可变的,写入的是数据的一个新版本,后台会定时gc,通过合并SSTable来清楚过期和被删除的数据。
5. Tablet 的迁移
- 跨节点迁移:为了负载均衡或处理故障,tablet 可以在不同的 tablet servers 之间迁移。这种迁移是透明的,对用户的查询和更新操作不会产生影响。
- 自动恢复:当一个 tablet server 失败时,Bigtable 可以自动将其负责的 tablets 重新分配到其他服务器上,以保持系统的高可用性和可靠性。
总结
在 Bigtable 中,tablet 是一个重要的数据分片单位,负责管理和存储特定范围的行数据。每个 tablet 内部使用 SSTables 来高效存储数据,同时结合 MemTable 和 WAL 来确保数据的实时性和持久性。通过动态分裂、合并、迁移等机制,Bigtable 能够高效地处理大规模数据,同时保持良好的性能和可伸缩性。
为什么要用chubby?GFS不是在Master已经实现了分布式锁了吗?
Bigtable 依赖于 Chubby 作为其协调服务,主要是因为 Chubby 提供了以下关键功能,这些功能对于 Bigtable 的运行和管理至关重要。虽然 Google 文件系统(GFS)确实有分布式锁的实现,但 Chubby 和 GFS 的角色和功能有所不同。下面是 Chubby 对 Bigtable 的重要性和它提供的独特功能的详细说明:
1. 协调与一致性
- 分布式锁管理:Chubby 提供了可靠的分布式锁服务,用于管理对共享资源的访问。虽然 GFS 也实现了分布式锁,但 Chubby 的锁服务更加灵活和高效,特别是在处理多个协调任务时。
- 配置管理:Chubby 提供了集中式的配置管理功能,允许 Bigtable 系统中的各个组件(如 tablet servers)在启动和运行时获取和更新配置信息。这种集中式管理简化了配置的统一和一致性保证。
- 选举机制:Chubby 用于选举领导者或协调者,这在分布式系统中对于管理系统状态和决策非常重要。例如,在 Bigtable 中,Chubby 帮助选举出主服务器或协调者,确保系统中只有一个活跃的领导者,避免了分布式系统中的冲突和不一致性。
2. 故障检测与恢复
- 心跳机制:Chubby 使用心跳机制来检测服务的健康状态和故障。它能迅速检测到节点的失效并采取适当的恢复措施,例如重新分配任务或重新选举领导者。
- 持久化状态:Chubby 确保关键元数据和协调状态的持久化,这些状态对于系统的一致性和恢复至关重要。在系统恢复时,Chubby 可以提供一致的视图和状态。
3. 数据一致性和高可用性
- 强一致性:Chubby 提供了强一致性保证,所有对共享资源的操作都是原子性的,并且所有的客户端都看到相同的状态。这种一致性对于 Bigtable 来说是必要的,特别是在进行元数据管理和协调任务时。
- 高可用性:Chubby 被设计为一个高可用的服务,确保即使在部分故障的情况下,系统仍然能够正常运作。它通过复制和容错机制实现高可用性,保证了系统的稳定性。
4. 与 GFS 的关系
- 不同的功能:虽然 GFS 提供了分布式锁的实现,但 GFS 的主要职责是提供高效、可靠的分布式文件存储。GFS 更多关注的是数据存储和访问,而 Chubby 专注于协调、配置管理和分布式锁的管理。
- 补充作用:GFS 和 Chubby 在大规模分布式系统中各自扮演不同的角色。GFS 提供底层的数据存储支持,而 Chubby 提供协调和一致性管理,两者共同支持 Bigtable 的稳定运行。
总结
Chubby 是 Bigtable 中关键的协调和一致性服务,它在分布式系统中扮演着重要的角色,特别是在管理配置、分布式锁、选举机制和故障恢复方面。虽然 GFS 提供了分布式文件存储和部分锁管理功能,但 Chubby 提供了更为全面和可靠的协调机制,满足了 Bigtable 对强一致性和高可用性的需求。
SSTable(Sorted String Table)是一种高效的磁盘数据存储格式,广泛用于 NoSQL 数据库和分布式存储系统中,如 Bigtable 和 LevelDB。以下是 SSTable 的主要特点和结构:
1. 数据结构
- 不可变文件:SSTable 文件一旦创建便不可更改。这种不可变性有助于提高读操作的效率,并简化了并发访问的管理。
- 有序存储:SSTable 存储的数据按照键值对的键进行排序,这使得范围查询和快速检索非常高效。
2. 主要组件
- 数据块:实际存储键值对的部分,通常按块存储在文件中。每个块包含一系列的有序键值对。
- 索引块:提供对数据块的索引,以便快速定位特定键的存储位置。
- 元数据:包含有关文件结构的信息,如文件的版本、数据块的位置等,通常包括一个文件头部和尾部的索引。
3. 操作过程
- 写入数据:
- 数据首先被写入内存中的结构(如 MemTable)。
- 当 MemTable 满时,它会被写入为一个新的 SSTable 文件。
- 读取数据:
- 读取操作首先检查索引块以找到数据块的位置信息。
- 然后从数据块中读取具体的数据。
4. 优点
- 高效读取:有序的存储和索引结构使得按键范围查询非常高效。
- 写入性能:由于 SSTable 是不可变的,写入操作不会影响现有的数据,减少了写操作的复杂性。
- 压缩与合并:SSTable 文件可以通过压缩和合并操作(如合并多个 SSTable 文件)来优化存储空间和查询性能。
5. 应用
- 范围查询:由于数据是有序存储的,SSTable 适合范围查询和按键排序操作。
- 增量写入:在写入新数据时,系统通常创建新的 SSTable 文件,并在后台将旧文件合并和压缩,以保持高效的读写性能。
总结
SSTable 是一种高效的磁盘存储格式,通过将数据有序存储和使用索引结构,提供了快速的读取性能和可靠的写入操作。它在分布式数据库和存储系统中扮演着关键角色,支持高效的数据检索和存储管理。
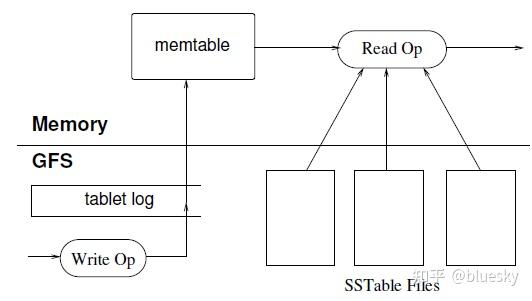
写操作
当一个写操作到达 tablet server 时,它会检查写操作是否格式正确(well-formed),以 及发送者是否有权限执行这次操作。
鉴权的实现方式是:从 Chubby 文件读取允许的写者列表(writer list)(在绝大多 数情况下,这次读都会命中 Chubby 客户端的缓存)。
一次合法的写操作会记录到 commit log。为了提高小文件写入的吞吐,我们使用了批量 提交(group commit)技术 [13, 16]。写操作被提交后,它的内容(数据)就会/才会 插入到 memtable。
读操作
一次读操作到达 tablet server 时,也会执行类似的格式检查和鉴权。
合法的读操作是在 SSTable 和 memtable 的合并视图上进行的(executed on a merged view of the sequence of SSTables and the memtable)。 由于 SSTable 和 memtable 都是按词典顺序排序的,因此合并视图的创建很高效。
在 tablet 分裂或合并时,读或写操作仍然是可以进行的。
Bloom
Bloom 过滤器可以判断一个 SSTable 是否包含指定行/列对(row/column pair)对应的 数据。对于特定的应用来说,给 tablet server 增加少量内存用于存储 Bloom 过滤器,就 可以极大地减少读操作的磁盘访问。
在 Bigtable 中,行和列的概念与传统关系型数据库中的行和列有显著区别。Bigtable 是一个列族存储型的 NoSQL 数据库,主要由 Google 设计,用于处理大规模的数据集。下面是 Bigtable 中行和列的区别及其结构特点:
1. 行(Row)
- 行键(Row Key):每一行通过一个唯一的行键来标识。行键是数据的主要索引,通常用于快速检索数据。
- 行的存储:数据按照行键进行排序,所有属于同一行的列族数据会被存储在一起。这使得读取某一行的数据非常高效。
2. 列(Column)
- 列族(Column Family):Bigtable 使用列族来组织列。每个列族包含多个列,列族用于将相关的列组合在一起,以便于进行存储和访问。列族有助于优化存储和查询性能。
- 列(Column):在 Bigtable 中,列的定义非常灵活。列是以列族为前缀的,例如
family:column。每列可以存储多个版本的数据。 - 动态列:与传统关系型数据库中固定的列不同,Bigtable 的列是动态的。即一个行可以拥有不同的列,列名可以是动态添加的,不需要预先定义所有列。
3. 区别
-
结构化与灵活性:
- 在关系型数据库中,列是固定的,必须在创建表时定义所有列,并且每行都有相同的列。
- 在 Bigtable 中,列是动态的,可以在运行时添加,并且不同的行可以有不同的列。
-
存储与访问:
- 在关系型数据库中,行和列的数据通常是以表格的形式存储,行之间的存储位置可能不确定。
- 在 Bigtable 中,同一行的数据存储在一起,按行键排序,这有助于提高行级的读取性能。
-
数据模型:
- 关系型数据库中的列是表的一部分,所有行都遵循相同的列定义。
- Bigtable 中的列是分组在列族中的,列族将列组织在一起,使得相关的列共享存储空间和配置。
总结
- 行:由唯一的行键标识,所有属于同一行的列族数据存储在一起。
- 列:动态定义,可以是不同列族下的任意列,列族用于组织相关列,列族的数据存储可以独立配置。
这种设计使 Bigtable 能够高效地处理大规模的数据,同时灵活地应对数据结构的变化。
在 Hadoop 的官方文档中,也对 HBase 的架构做了说明:
HBase 使用了与 BigTable 非常类似的数据模型。用户存储数据行到特定的表中。一个数据行有一个可排序的 rowKey 和数量不定的列。这个表是稀疏的,只要用户愿意,这个表不同行可以有完全不同的列。
布隆过滤器
布隆过滤器是一种概率型数据结构,用于高效判断元素是否可能在一个集合中。它通过多个哈希函数将元素映射到一个位数组的不同位置,并将这些位置置为1。查询时,如果所有映射位置都是1,则元素可能存在;若任一位置为0,则肯定不存在。它空间效率高,但有误判率,即可能会错误地认为元素存在(假阳性),而不存在元素被判断存在的概率可以通过设计调整。不适合需要精确查找的场景,常用于大规模数据去重、缓存穿透预防等。
Exp
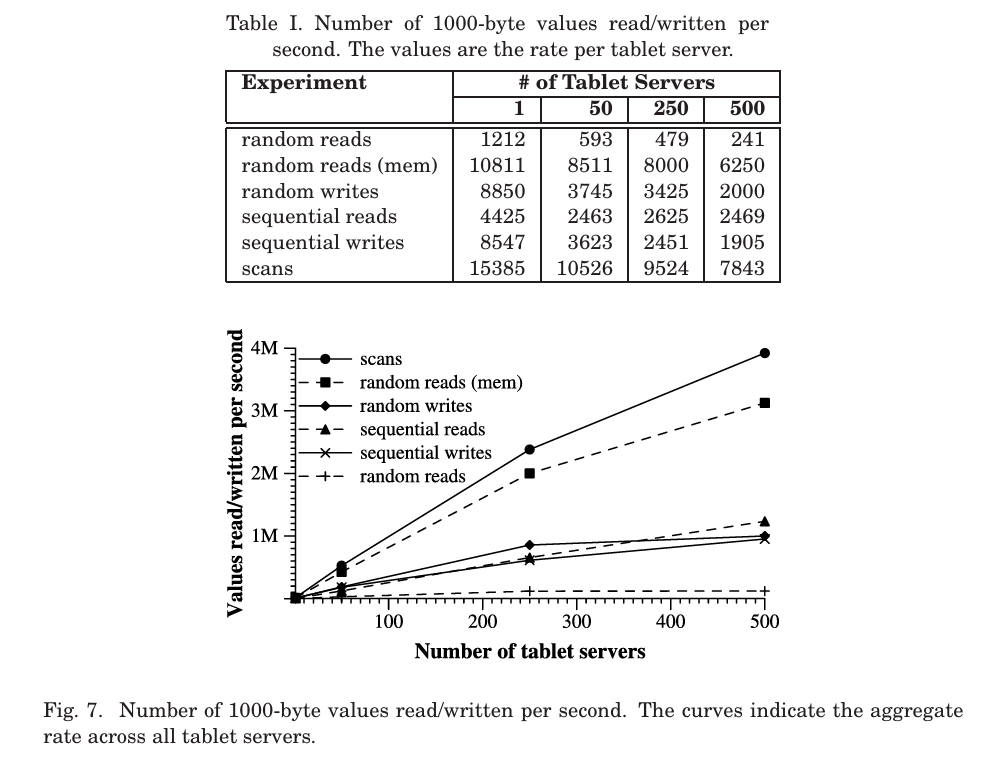
100台时 1M, 500台时4M,维持自己的分布式
Table I and Figure 7 provide two views on the performance of our bench marks when reading and writing 1000-byte values to Bigtable. The table shows the number of operations per second per tablet server; the graph shows the aggregate number of operations per second
We set up a Bigtable cluster with N tablet servers to measure the performance and scalability of Bigtable as N is varied. The tablet servers were configuredto use 1GBofmemoryandtowritetoaGFScellconsistingof1786machineswith two 400 GB IDE hard drives each. N client machines generated the Bigtable load used for these tests. (We used the same numberof clients as tablet servers to ensure that clients were never a bottleneck.) Each machine had two dual core Opteron 2 GHz chips, enough physical memory to hold the working set of all running processes, and a single gigabit Ethernet link. The machines were arrangedin a two-leveltree-shapedswitched networkwith approximately100 200 Gb/s of aggregate bandwidth available at the root. All of the machines were in the same hosting facility and therefore the round-trip time between any pair of machines was less than a millisecond.
一个Hadoop的分布式数据库
HBase在HDFS之上提供了 高并发的随机写和支持实时查询 ,这是HDFS不具备的。
最大的问题在于:怎么在多机上查数据?
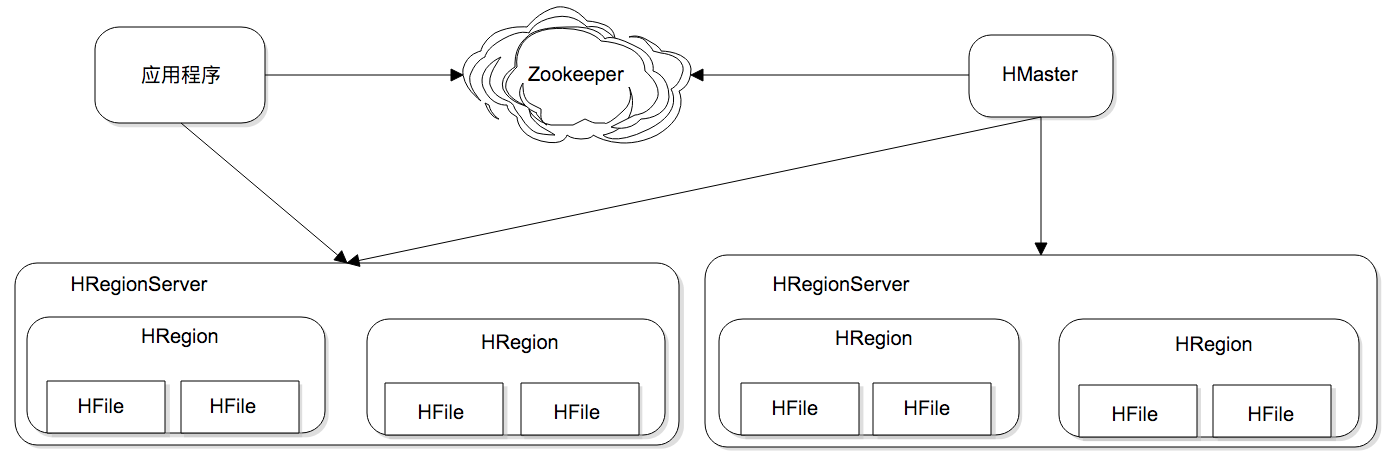
HBase为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。HBase的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现。
HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。当一个 HRegion中写入的数据太多,达到配置的阈值时,一个HRegion会分裂成两个HRegion,并将HRegion在整个集群中进行迁移,以使HRegionServer的负载均衡。
每个HRegion中存储一段Key值区间 $[key1, key2)$ 的数据,所有HRegion的信息,包括存储的Key值区间、所在HRegionServer地址、访问端口号等,都记录在HMaster服务器上。为了保证HMaster的高可用,HBase会启动多个HMaster,并通过ZooKeeper选举出一个主服务器。
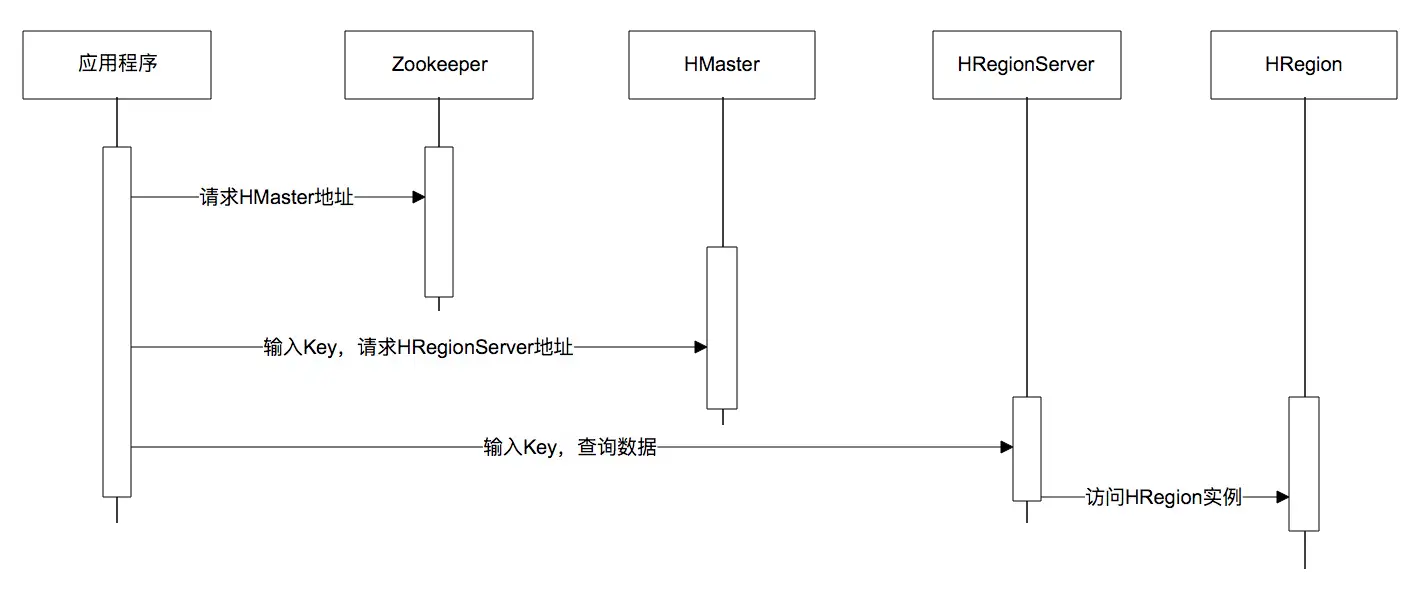
下面是一张调用时序图,应用程序通过ZooKeeper获得主HMaster的地址,输入Key值获得这个Key所在的HRegionServer地址,然后请求HRegionServer上的HRegion,获得所需要的数据。
合并
在 LSM Tree 中,合并操作(Merge)是一个关键的过程,用于优化存储结构和提高查询效率。合并的主要目标是减少磁盘上的数据碎片,并整理和压缩 SSTable 文件。下面是合并操作的详细步骤:
1. 触发合并
- 内存表满:当 MemTable 达到一定大小时,它会被转储到磁盘形成新的 SSTable 文件。这通常会触发合并操作,尤其是当新生成的 SSTable 文件与现有的 SSTable 文件在磁盘上需要进行整理时。
- 定期触发:为了维护良好的性能,系统会定期触发合并操作,而不仅仅在 MemTable 刷新时。
2. 合并过程
- 选择候选 SSTable:系统会选择需要合并的 SSTable 文件。通常会选择那些已经达到一定数量或空间的 SSTable 文件进行合并。
- 读取数据:从选择的 SSTable 文件中读取数据,通常会将其加载到内存中进行处理。合并过程中会将多个 SSTable 文件的数据读入内存。
- 排序与去重:在内存中将数据进行排序并去重,确保每个键值对在最终的 SSTable 文件中唯一。排序有助于高效地将数据写入新的 SSTable 文件。
- 写入新 SSTable:将整理后的数据写入一个新的 SSTable 文件。这是一个有序的文件,通常比旧的 SSTable 文件更大、更整洁。
- 替换和删除:将新的 SSTable 文件替换旧的 SSTable 文件。旧的 SSTable 文件在完成合并后会被删除,释放存储空间。
3. 合并策略
- 大小合并:根据文件的大小选择合并操作。例如,系统可能会合并大小较小的 SSTable 文件,生成一个更大的 SSTable 文件。
- 层次化合并:一些 LSM Tree 实现使用层次化策略,将数据分布在多个层次中,每个层次具有不同的大小和合并策略。例如,LevelDB 使用类似的策略来管理不同层次的 SSTable 文件。
4. 合并的优势
- 减少碎片:合并操作减少了磁盘上的数据碎片,优化了存储空间的利用。
- 提高读性能:合并后的 SSTable 文件更大、更有序,使得查询操作时能够更快速地找到数据,减少了多次查找的开销。
- 提升写性能:通过减少写操作中的随机读写,合并操作使得数据写入更加高效。
总结
合并操作在 LSM Tree 中是一个重要的维护过程,它通过整理和压缩 SSTable 文件来优化存储和读取性能。合并过程中涉及数据的排序、去重、以及写入新的 SSTable 文件,最终帮助减少磁盘碎片、提高读写效率。
B+Tree VS LSM-Tree
LSM Tree(Log-Structured Merge Tree) 是一种用于高效写入和读取的树形数据结构,广泛应用于数据库和存储系统中。它特别适用于处理大量的写操作,常见于像 LevelDB 和 RocksDB 这样的 NoSQL 数据库中。下面是 LSM Tree 的简单介绍:
1. 基本结构
- 内存表(MemTable):一个在内存中维护的有序数据结构,用于存储最近的写入操作。通常使用红黑树或跳表实现。
- 日志文件(Write-Ahead Log, WAL):所有写操作首先记录到 WAL 中,以确保数据不会丢失。如果内存表崩溃,可以通过 WAL 恢复数据。
- 磁盘表(SSTable):内存表的数据会定期刷新到磁盘上,形成一个或多个不可变的 SSTable 文件。每个 SSTable 文件都是有序的,支持高效的读操作。
2. 工作流程
-
写入:
- 写操作首先进入 MemTable,并且记录到 WAL 中。
- 当 MemTable 达到一定大小后,它会被转储到磁盘上,形成新的 SSTable 文件。
-
合并(Merge):
- 定期进行合并操作,将多个 SSTable 文件合并成一个新的 SSTable,以减少磁盘上的数据碎片。
- 合并操作会将多个较小的 SSTable 文件合并成一个较大的文件,并且整理和压缩数据,优化查询性能。
-
读取:
- 读取操作首先查找 MemTable,然后查找各个 SSTable 文件。如果 MemTable 中没有找到数据,再依次查找 SSTable 文件。
- 读取时,通过内存中的索引和每个 SSTable 文件的索引,可以快速定位到数据。
3. 优点
- 高写入性能:由于写操作首先进入内存表,写入速度较快,减少了磁盘的随机写入。
- 高效读操作:虽然 SSTable 文件是不可变的,但通过索引和合并操作,读取操作仍然保持高效。
- 空间优化:合并操作减少了数据的重复和碎片,提高了存储空间的利用率。
4. 适用场景
- 写密集型应用:LSM Tree 适用于写入频繁、读写比例不均衡的场景,如日志处理、大规模数据存储等。
总结
LSM Tree 通过在内存中维护一个有序的 MemTable 和定期将数据刷新到磁盘上的 SSTable 文件,优化了写入和读取性能。合并操作和空间优化机制使其非常适合高写入负载的应用。
1707.05354 (arxiv.org)
IPDPS 2018

lWe develop a dynamic dictionary data structure for the GPU, supporting fast insertions and deletions, based on the Log Structured Merge tree (LSM). Our implementation on an NVIDIA K40c GPU has an average update (insertion or deletion) rate of 225 M elements/s, 13.5x faster than merging items into a sorted array.
We proposed and implemented the GPU LSM, a dynamic dictionary data structure suitable for GPUs, with fast batch update operations (insertions and deletions) as well as a variety of parallel queries (lookup, count, and range). We f ind that we can update the GPU LSM much more efficiently than we can a sorted array, especially for small batch sizes, at the cost of a small constant factor in query time
传统关系型数据采用的底层数据结构是B+树,那么同样是面向磁盘存储的数据结构LSM-Tree相比B+树有什么异同之处呢?
LSM-Tree的设计思路是,将数据拆分为几百M大小的Segments,并是顺序写入。
B+Tree则是将数据拆分为固定大小的Block或Page, 一般是4KB大小,和磁盘一个扇区的大小对应,Page是读写的最小单位。
在数据的更新和删除方面,B+Tree可以做到原地更新和删除,这种方式对数据库事务支持更加友好,因为一个key只会出现一个Page页里面,但由于LSM-Tree只能追加写,并且在L0层key的rang会重叠,所以对事务支持较弱,只能在Segment Compaction的时候进行真正地更新和删除。
因此LSM-Tree的优点是支持高吞吐的写(可认为是O(1)),这个特点在分布式系统上更为看重,当然针对读取普通的LSM-Tree结构,读取是O(N)的复杂度,在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。
而B+tree的优点是支持高效的读(稳定的OlogN),但是在大规模的写请求下(复杂度O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
还有一点需要提到的是基于LSM-Tree分层存储能够做到写的高吞吐,带来的副作用是整个系统必须频繁的进行compaction,写入量越大,Compaction的过程越频繁。而compaction是一个compare & merge的过程,非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响,当然我们可以禁用自动Major Compaction,在每天系统低峰期定期触发合并,来避免这个问题。
阿里为了优化这个问题,在X-DB引入了异构硬件设备FPGA来代替CPU完成compaction操作,使系统整体性能维持在高水位并避免抖动,是存储引擎得以服务业务苛刻要求的关键。
总结
本文主要介绍了LSM-Tree的相关内容,简单的说,其牺牲了部分读取的性能,通过批量顺序写来换取了高吞吐的写性能,这种特性在大数据领域得到充分了体现,最直接的例子就各种NoSQL在大数据领域的应用,学习和了解LSM-Tree的结构将有助于我们更加深入的去理解相关NoSQL数据库的实现原理,掌握隐藏在这些框架下面的核心知识。
整个SSTable的实现分为memTable和磁盘上的SSTable。在内存里使用的是skip-list。所以写的操作只是写内存,非常的快。而内存写满之后就会把这个memTable变成一个immutable的memTable。同时开一个新的可以写的memTable另外一个线程则会把这个immutable的内存表变成一个磁盘上的SSTable。当这个转变完成以后immutable的内存表被释放。如此往复磁盘上会产生很多的SSTable。这就需要compact。SSTable是有level1, level2,。。。的。其中进到level1的compact叫做minor compact。后面还有major compact。从level2开始以后任意两棵树的key之间不会有overlap,但是在level1这并不guarantee。
所以我们的一个读操作要读memTable,immutable memTable,level1的tree,和level2以及以下的level的1棵树。这说明读的操作相对写的操作会更贵一些。大家需要注意的是,如果我们访问的是最新的版本,那么有可能会在内存里,所以这个设计对于读的操作主要是优化了新版本的读。对于cool data的读则要慢很多。顺便补充一句,Facebook的copycat RocksDB和LevelDB最主要的区别据说是引入了一个叫做universal compact的东西。当然我没有研究过这个codebase,不清楚universal compact到底有多牛。
当然,就像任何一个类似的系统一样,BigTable的recovery基于log,所有的写操作进内存之前写进log。LevelDB的log format并不是太难懂,是经典的append only的操作。基于log的读写恢复是任何一个系统的基础了。我就不再展开叙述。