
ATC25 Colocating ML Inference and Training with Fast GPU Memory Handover
- Paper Reading
- 2026-01-15
- 292 Views
- 0 Comments
- 1534 Words
今天yf来分享一篇来自IPADS的ATC25文章。
Colocating ML Inference and Training with Fast GPU Memory Handover
简短点评:依旧IPADS特有的大工程,TVM+vLLM+NCCL+Pytorch
开组会大家一起问了很多问题。
https://ipads.se.sjtu.edu.cn/_media/publications/sirius-atc25.pdf
这篇文章做什么
设计了一个在DNN/小LLM 训练+推理场景下能高效协同的系统。
大概idea就是,训练作为一个常规workload运转在GPU里,推理随时可能插入。我们的目标是当推理请求来时,快速的给推理任务腾出内存。
目前的两个方法都是狗屎:直接静态的训练转推理,或者用同一内存管理,都有问题。
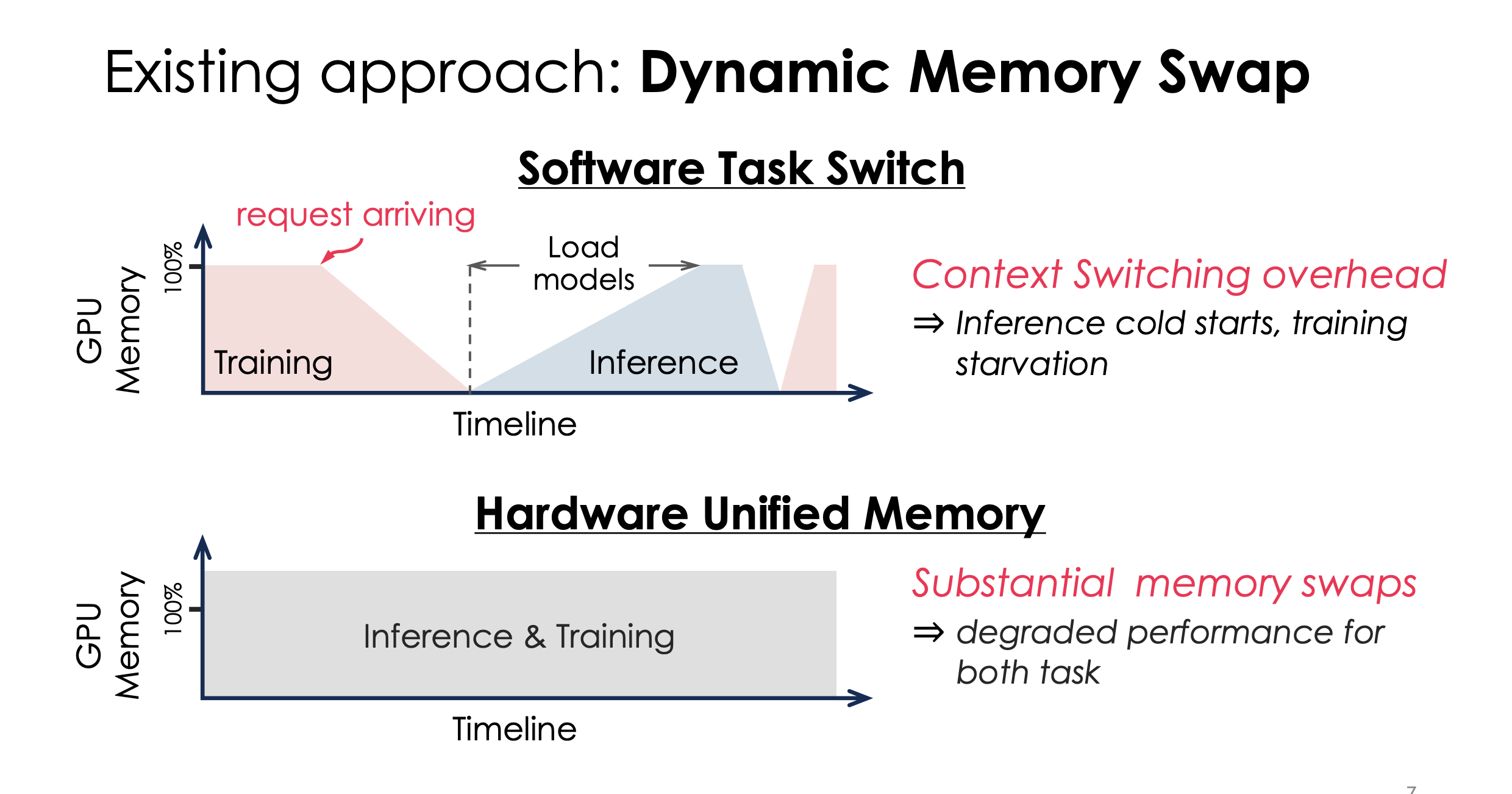
提问:Load models怎么优化
答:后面会讲
所以,这篇文章的设计是更动态的内存管理
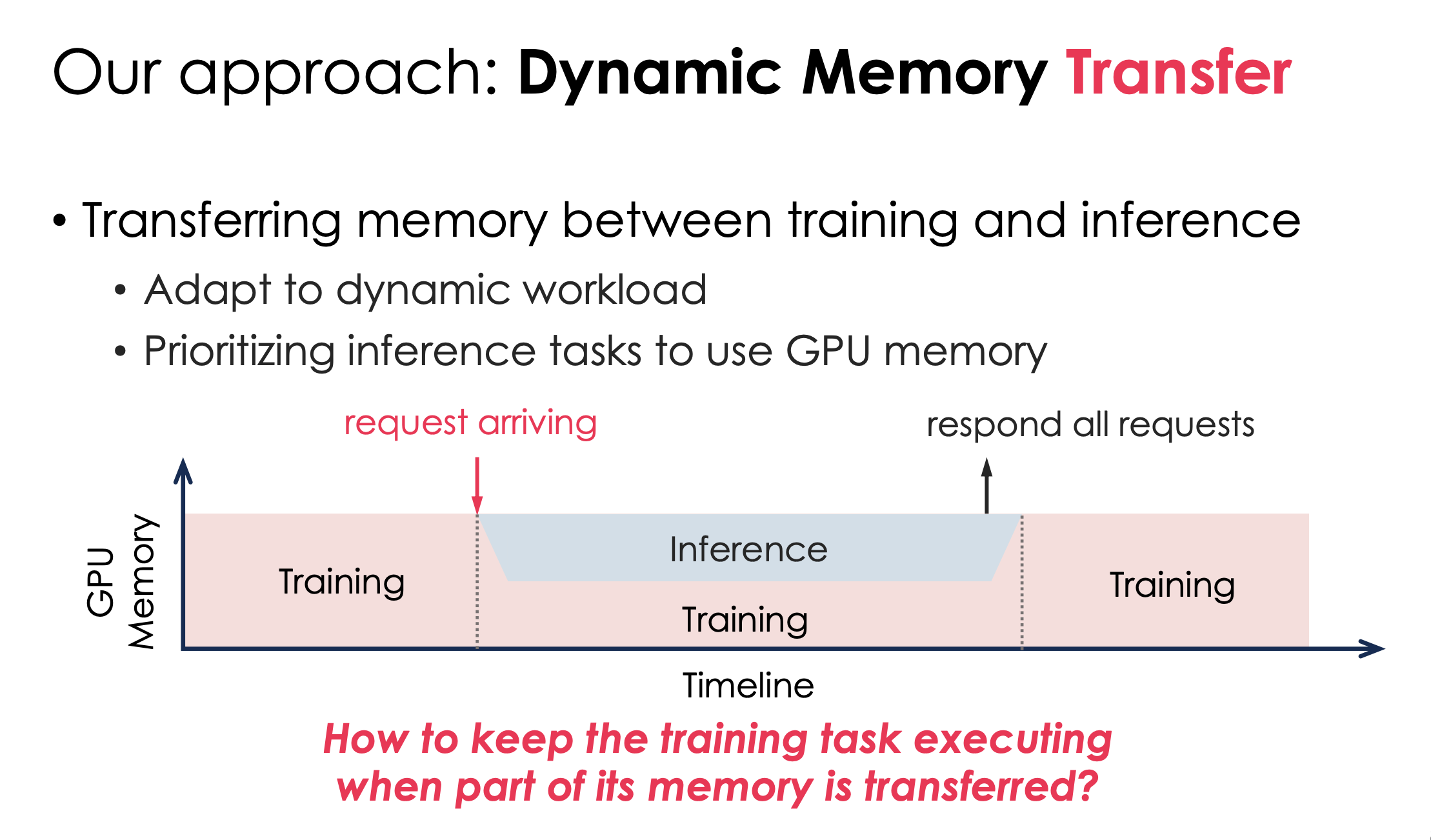
问:真的有工业界有这个场景吗?
我们讨论了下,感觉最有可能的是小公司的40台GPU,那可能随时会冒几个请求
那么怎么样才能压低这个Training的内存呢?他们发现只要把training 的batchsize改低就可以了。

这样,中间就能直接给inference空间
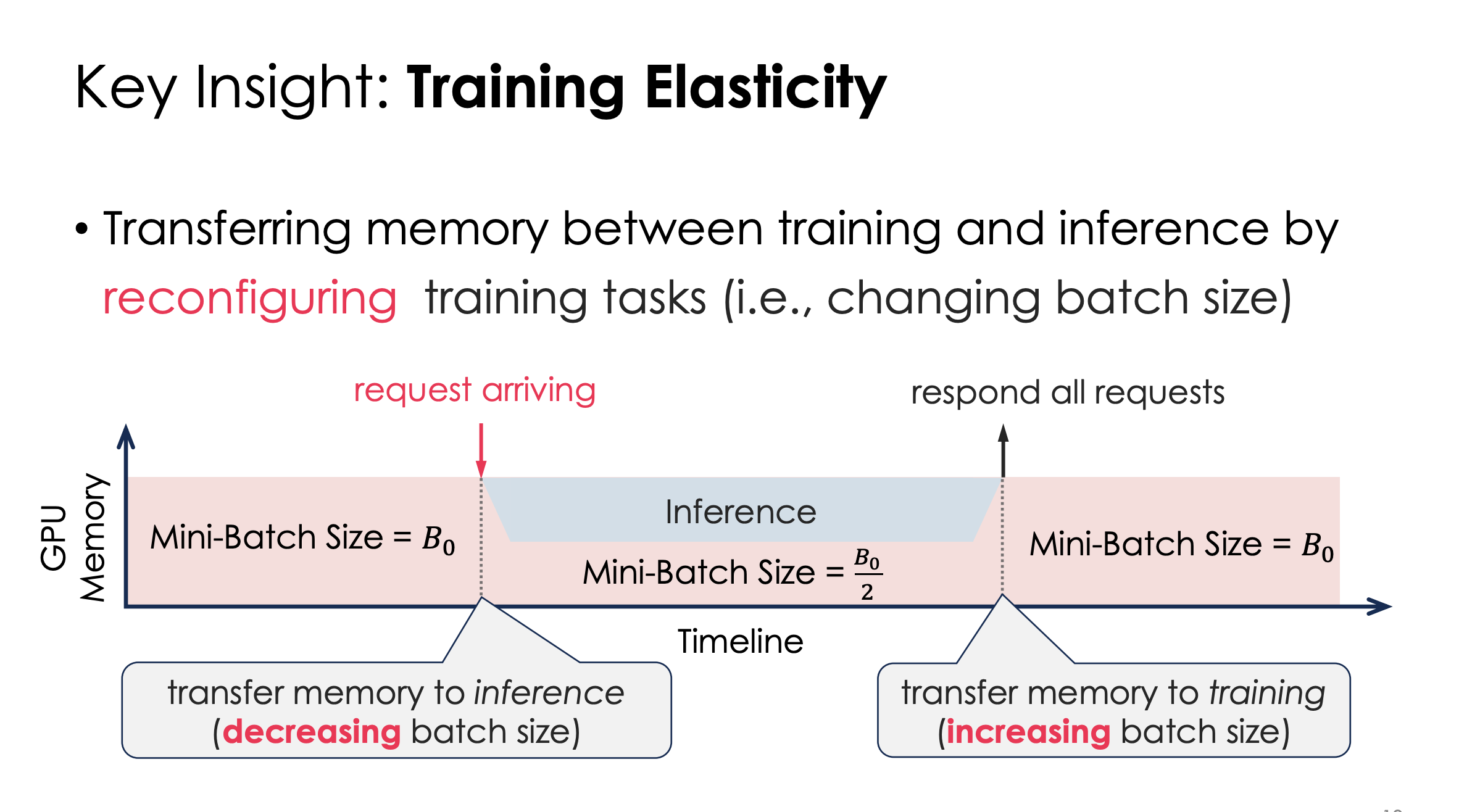
提问:为什么图这里是B0/2?
答:随便给的。
但是改低后,还是有release+alloc+load 的250ms巨大开销,远大于推理10ms执行开销。这部分能压缩吗?
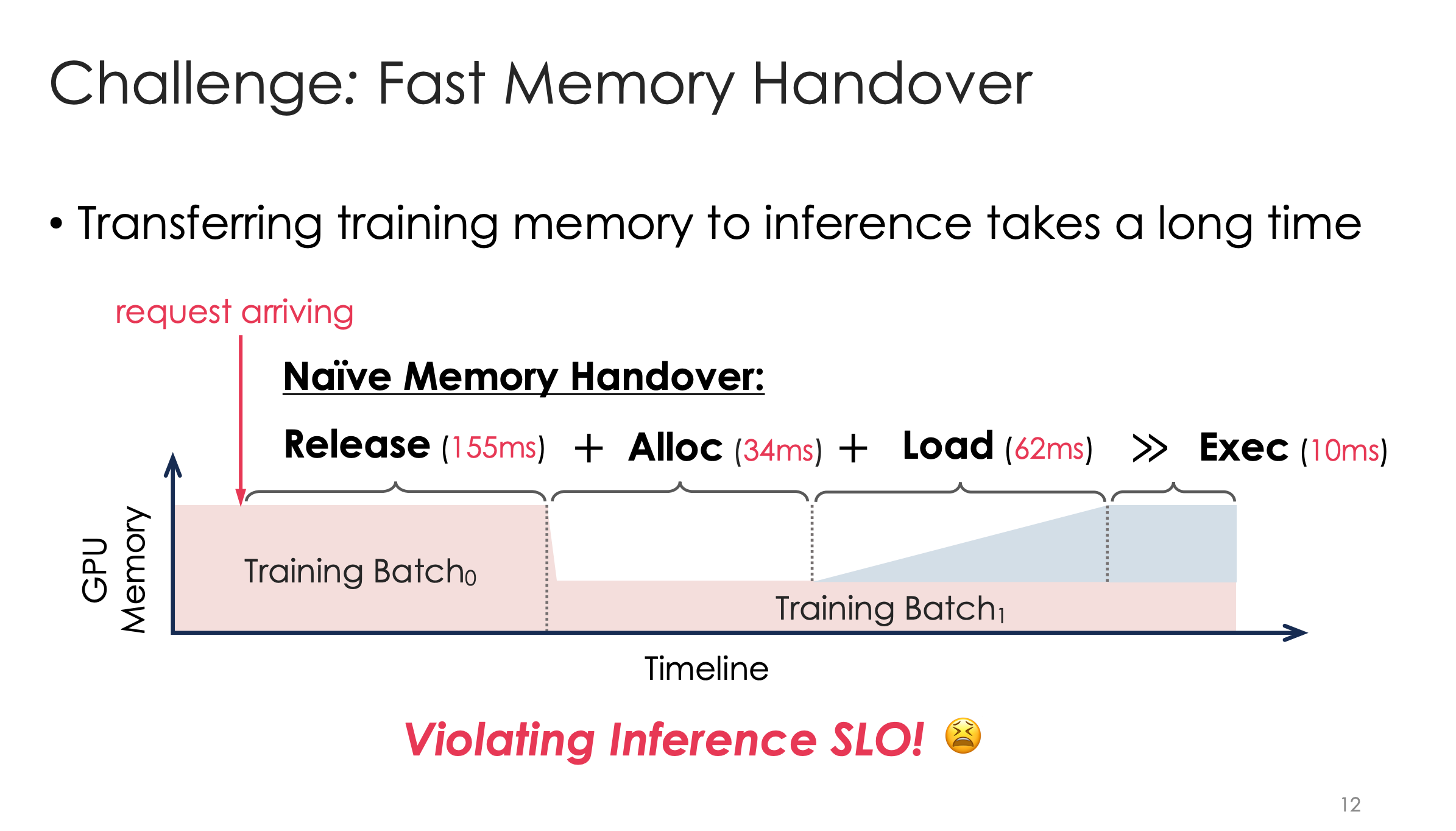
优化1 推理来时,丢弃目前batch
如图,如果是模型更新阶段,就不丢弃,但是如果还在算反向传播什么的,就要中断,然后让推理上。

这里一个工程设计是,如何中断?他们的操作很粗暴,就是给训练会发送kernels全部统一加入一个CPU队列。在kernels加入队列后,他们再被顺序执行到GPU上。此时只要控制说是否加入队列,就可以控制GPU是否发射。
其实很像是用户态的一个控制阀门,就不用从OS底层去中断它。

lkx问:这样不是多了个Queue开销?
答:对,但是CPU上这个开销不大
优化2 训练+推理的统一内存池
之前的操作是,训练一个进程,推理一个进程,两个内存互不干扰。这挺好的。但是性能差,因为如果有内存从训练空间给到推理空间,就一定有switch。
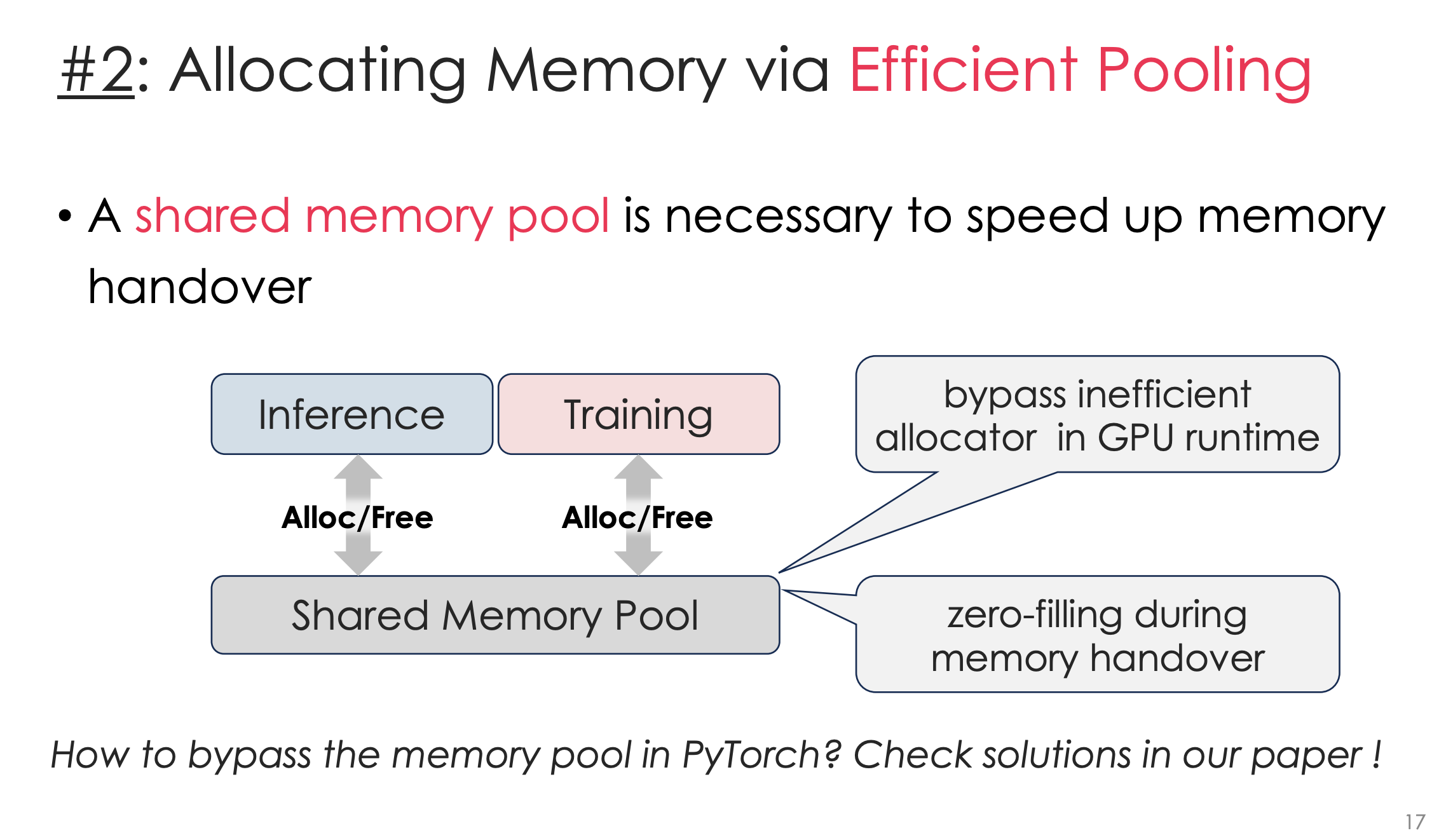
这里PPT问如何处理memory pool,文章是这样的:
大概就是,他们设计了一个Pytorch内的malloc。就我每次alloc时,可能会给train或者给inference。如果我还在train,我就保持不变,否则我就消掉。这样能一个统一的mem pool就能给两者提供服务。
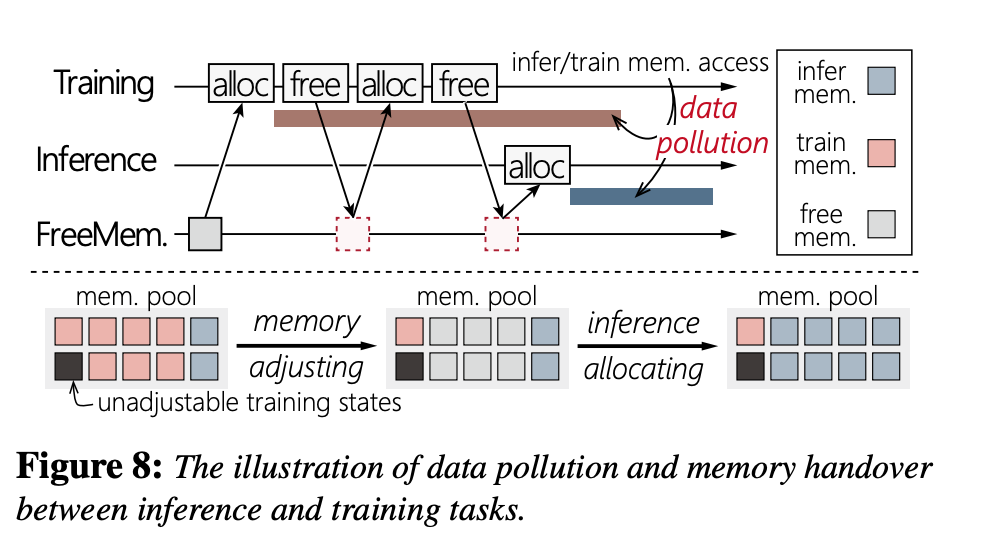
文章还讨论了pollution的问题。大概就如图,如果Inference已经拿到了那个mem block,此时Train那边的mem指针就不行了。文章的做法是这个Pytorch内malloc会根据mem block的一个数字比如int来表示这块内存是否valid。
fxl问:这样cuda能知道这些吗?
答:不能,相当于开始我就cuda malloc一大块,然后我在上层管理我的内存使用。
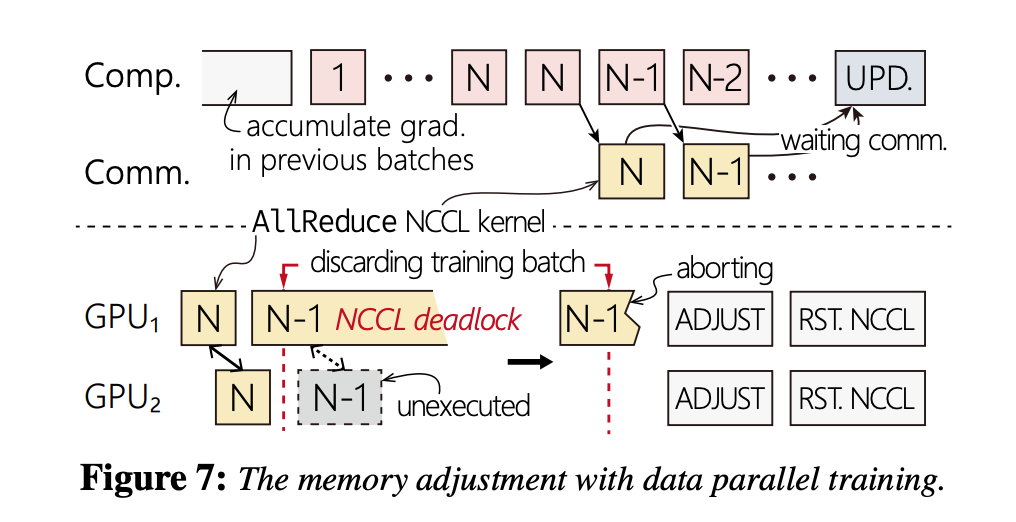
优化3
NCCL的问题问了一堆
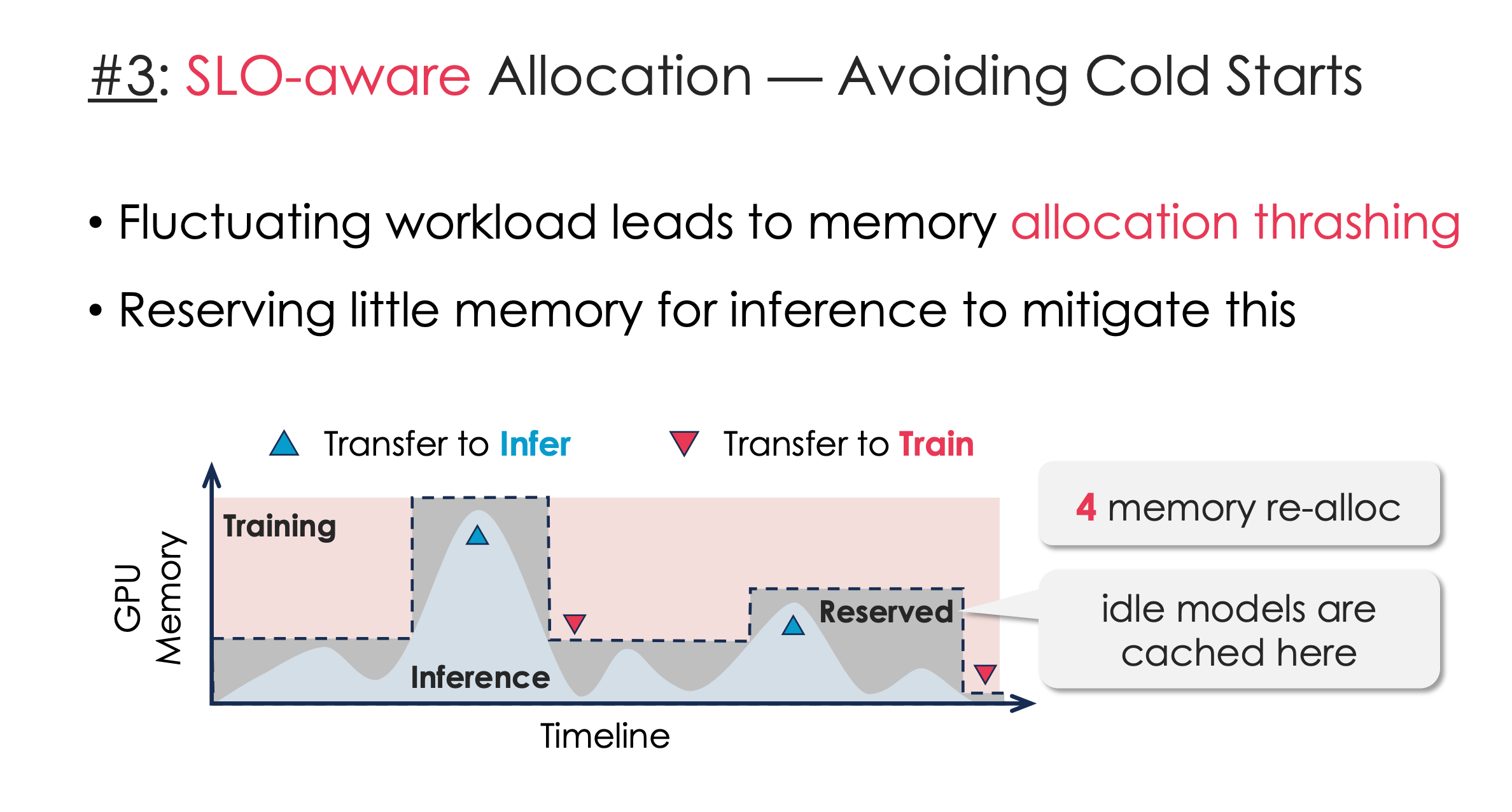
SLO aware 的热启动推理
什么时候加载推理模型?作者用一个调度算法来预测。

这个调度算法来源于一个排队论模型。M/G/1 是 Kendall 记号中的一种排队模型,含义是:
M / G / 1 = 到达过程 / 服务时间分布 / 服务器数量
具体是:
-
M (Markovian):到达过程是 泊松过程 (Poisson process)
👉 也就是说:- 请求到达是随机的
- 到达间隔服从 指数分布
- 平均到达率是 λ
-
G (General):服务时间服从 任意分布(一般分布)
👉 这里表示:- 每个 inference 的处理时间可能不一样
- 可能有 cache miss / re-init / cold start / paging 等
- 不假设是指数分布
-
1:单服务器
👉 意味着:- 系统一次只能处理 一个 inference 请求
- 其他请求都在排队


由此文章发现设计成2W是最好的

提问:这个排队模型是否适用于一般的推理:
答:是适用的。但是一般推理是没有这个training带来的资源限制。
老板问:你们没有学过时序分析?这个会讲这方面知识
答:没有,不会。
这样起到削峰填谷作用:
实验
对比了用静态分配等操作。看起来还挺工业界的。

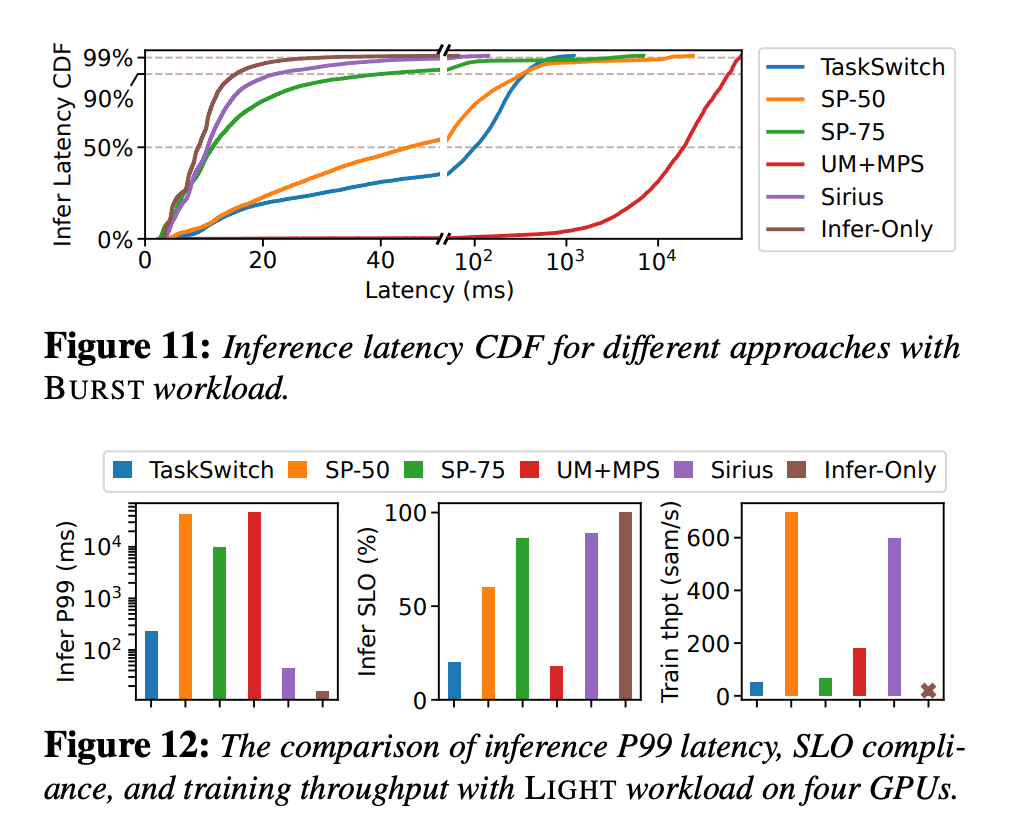
Haibin问: 这个CDF图怎么看?
qyf答:你划竖线,比如这里,20ms限制有97%-99%这样,说明99%的latency都在20ms内。
实验的问题2
问:你看你这个Sirius,为什么前面两个图比SP75和Infer Only低,后面又比他们都高?
老板答:对于推理来说,是不是直接强硬分为SP75,推理拿25,就可以满足推理,所以TTFT和TBT很高了。而只做infer,TTFT和TBT当然没有干扰也是最快的。
对于第三张,是Train训练的吞吐。那Infer only自然没有,然后SP-75就低了。说明,如果没有infer,sirius就能到100给train。而有request来后,总体的利用率大于SP75,也就是能保证高的利用率
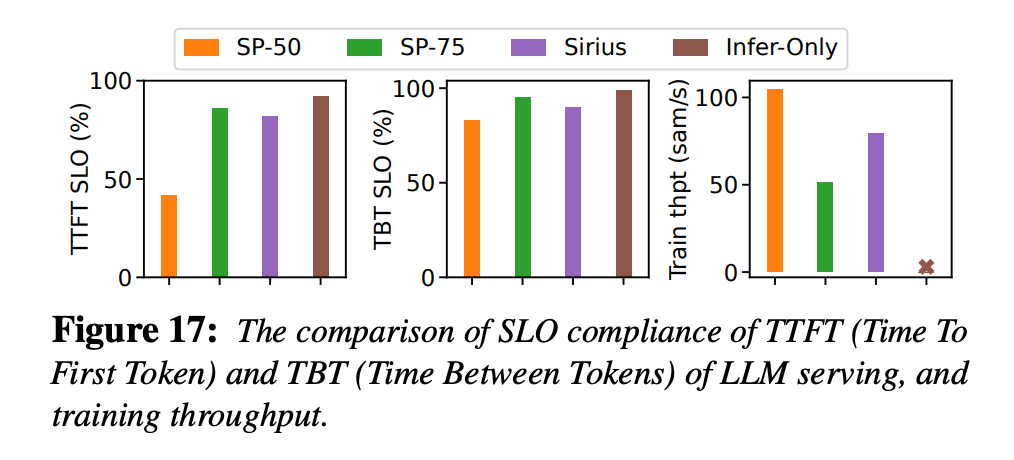
加速后效果:
还是挺猛的
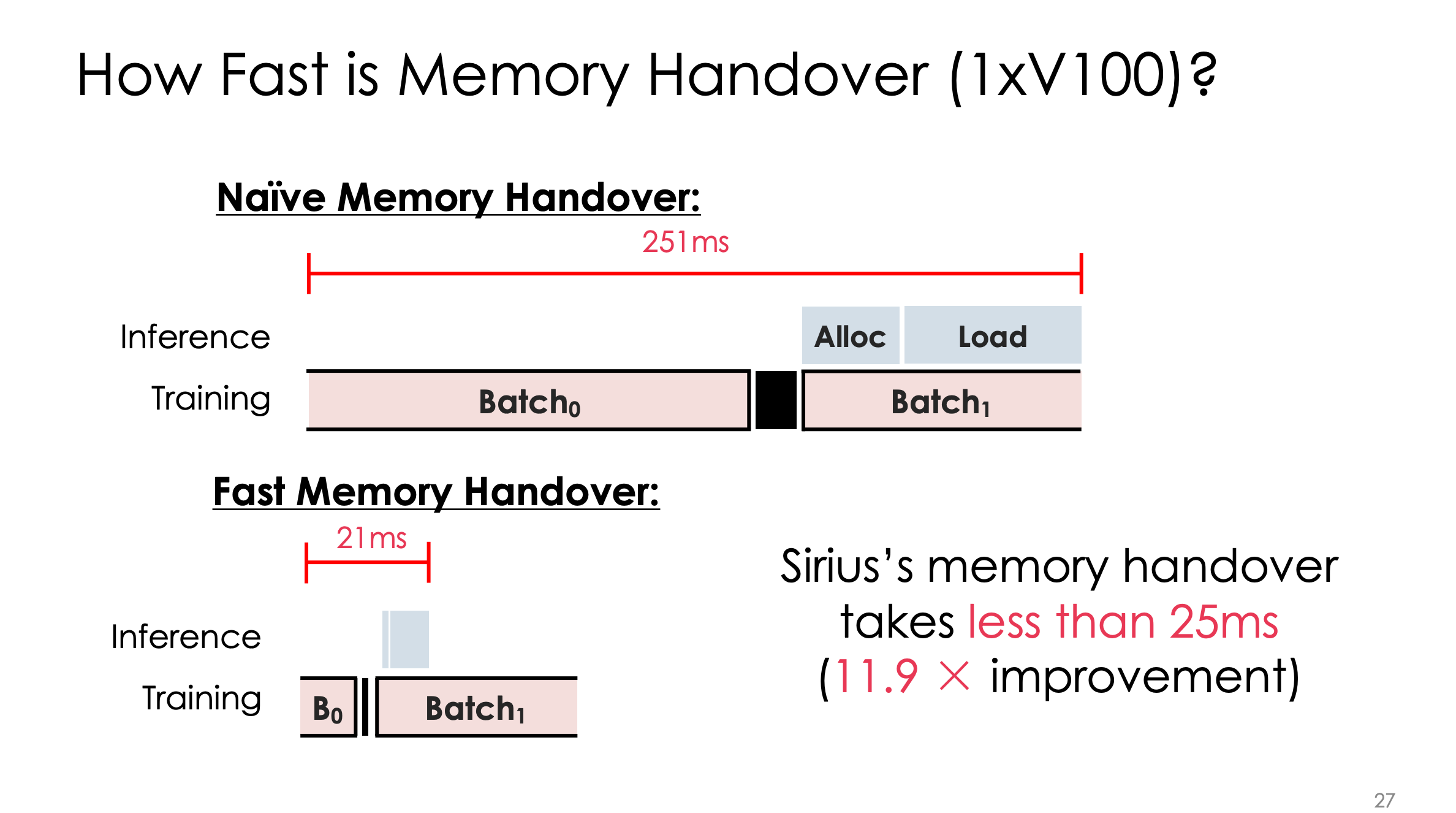
看起来像是量化会做的事情哈哈哈哈,最后还是殊途同归。
多卡:NCCL死锁
这个问题发生在用CPU Queue限制kernels后。
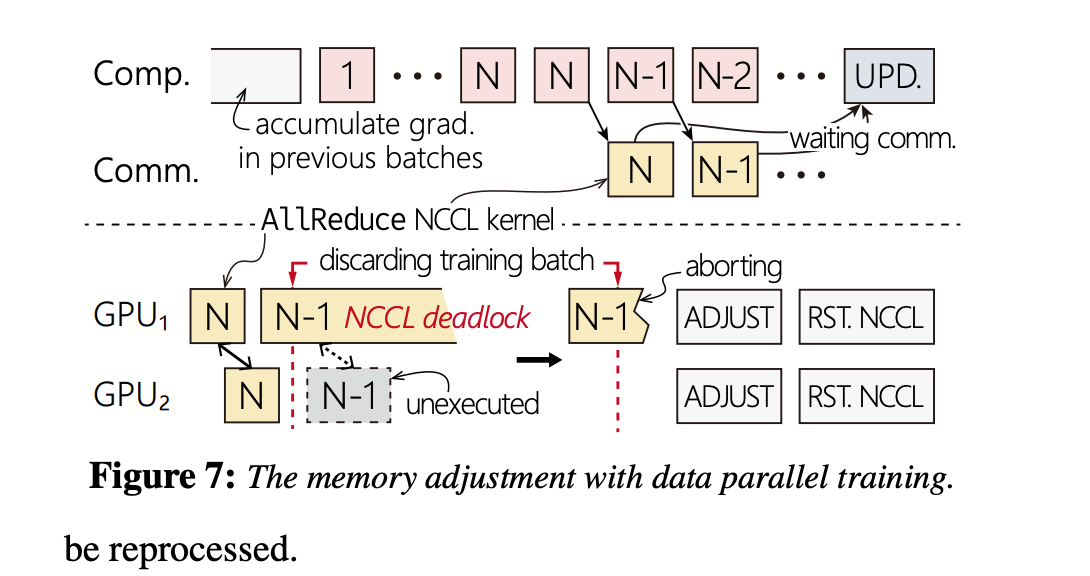
这里我们争执了一会,第一是一致性的问题,怎么保证每个kernel在多卡都是同一个,不会其中超出了。另一个是为什么会死锁。
发现这个是一个工程问题,他们解决方法是在NCCL上改了一层,尝试骗NCCL说可以结束通信了,避免死锁。然后多卡同一个,是用一个令牌token或者像保存copy来搞定的。
点评
工程量挺大,要懂NCCL+Pytorch+TVM+vLLM,挺累的。辛苦了
我感觉这套东西能做更多,这些代码还可以做很多事情。挺好的框架