
ATC24 Power-aware Deep Learning Model Serving with u-Serve
- Paper Reading
- 2025-08-26
- 381 Views
- 0 Comments
- 1154 Words
Power-aware Deep Learning Model Serving with u-Serve
这篇文章是发表于2024年 USENIX ATC'24 的论文,标题为《Power-aware Deep Learning Model Serving with μ-Serve》,作者来自伊利诺伊大学厄巴纳-香槟分校和IBM Research。论文聚焦于深度学习(DL)模型服务(即推理)中的功率优化问题,提出一个名为μ-Serve的新型功率感知模型服务框架,旨在在GPU集群中减少能耗,同时保持服务水平目标(SLO,如延迟或吞吐量要求)。
主要内容总结
问题与挑战
- 随着大型DL模型(如Transformer和生成模型,如GPT系列)的普及,模型服务已成为云系统中主要的能耗来源(据Google和AWS数据,推理占ML能耗的60%-90%)。
- 现有模型服务系统(如AlpaServe)关注性能(延迟、吞吐量)或准确性,但忽略功率优化。
- 挑战包括:
- C1:难以确定最佳GPU频率,以平衡功率节省和SLO(现有DVFS基于利用率,但不精确)。
- C2:生成模型的自回归性质导致执行时间非确定性,易受头对线阻塞影响,限制功率节省空间。
- C3:GPU不支持细粒度(per-core)频率缩放,导致模型分区混合时功率优化受限。
关键创新与设计
μ-Serve分为离线阶段(模型准备)和在线阶段(运行时服务),核心组件包括:
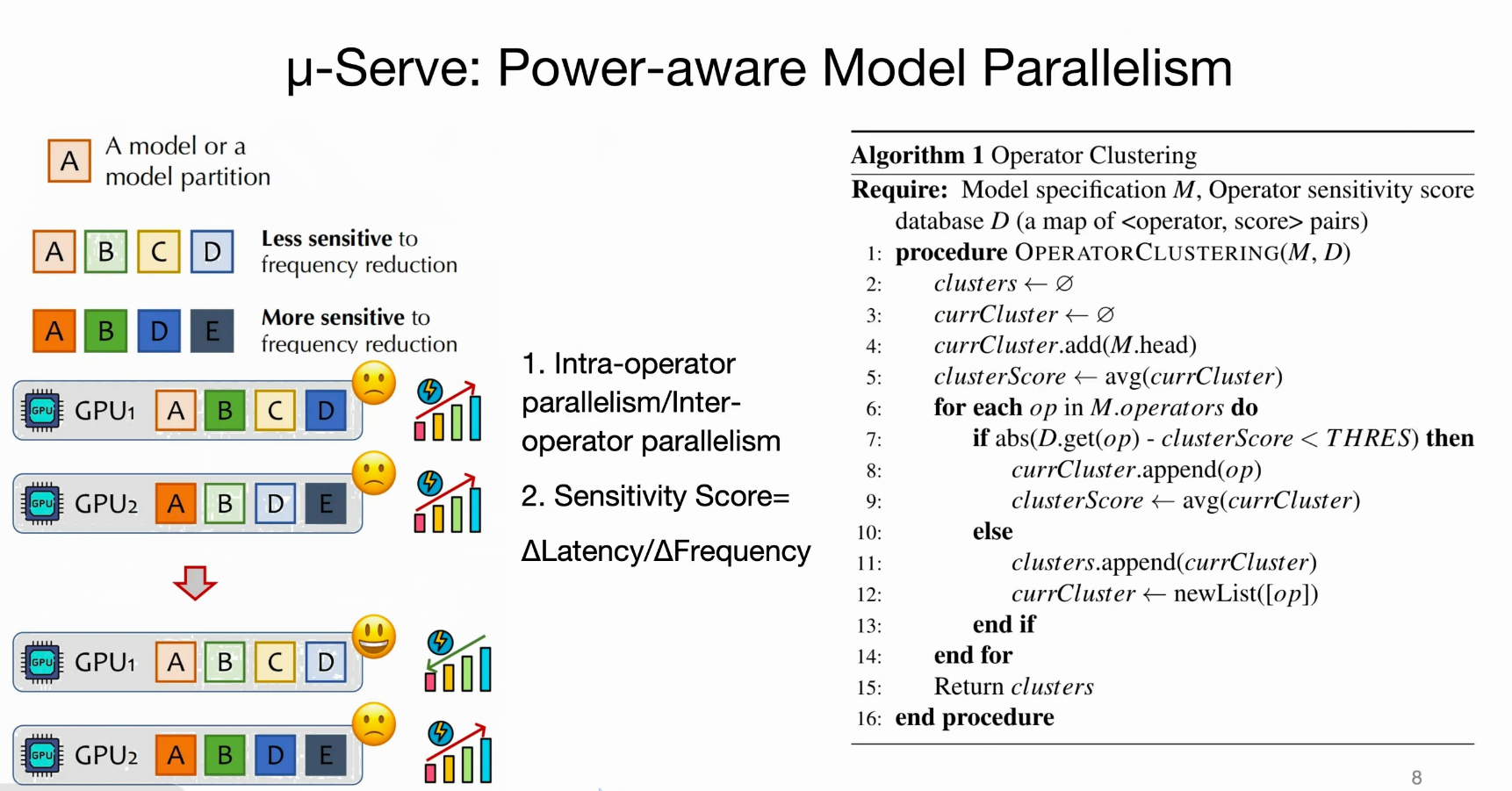
- 功率感知细粒度模型供应:
- 分析模型操作符(operator,如矩阵乘法)的“敏感度”(对GPU频率变化的延迟影响)。
- 使用模型并行(intra/inter-operator)生成分区计划,确保敏感操作符不混合,以最大化功率节省机会。
- 扩展AlpaServe的自动并行化算法,实现功率感知分区和放置。
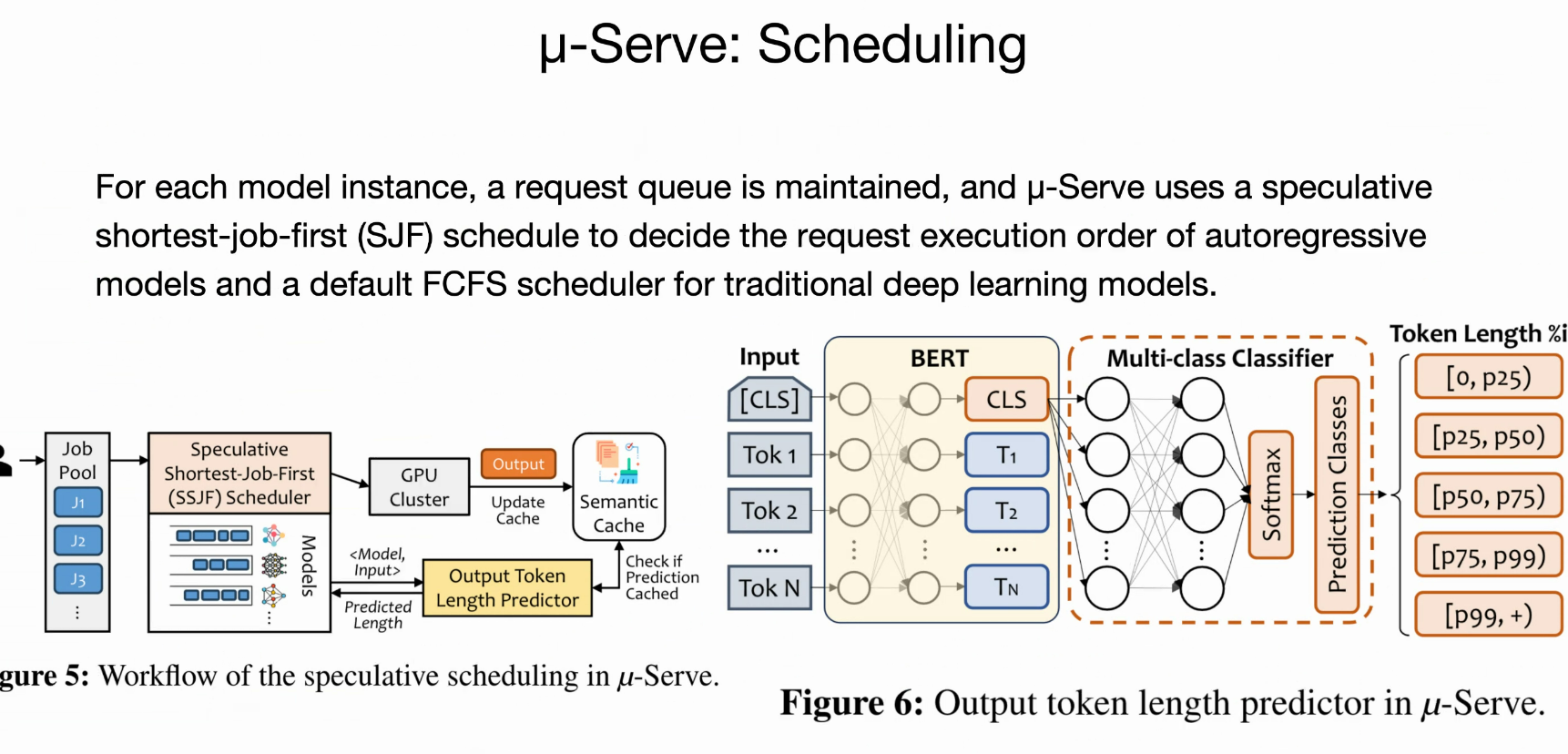
- 推测性请求服务:
- 为生成模型引入轻量代理模型(基于BERT的分类器),预测输出令牌长度(主导执行时间),以实现推测性最短作业优先(SSJF)调度。
- 结合语义缓存(semantic cache)存储热门查询的真实长度,避免头对线阻塞,提高SLO达标率和功率节省空间。
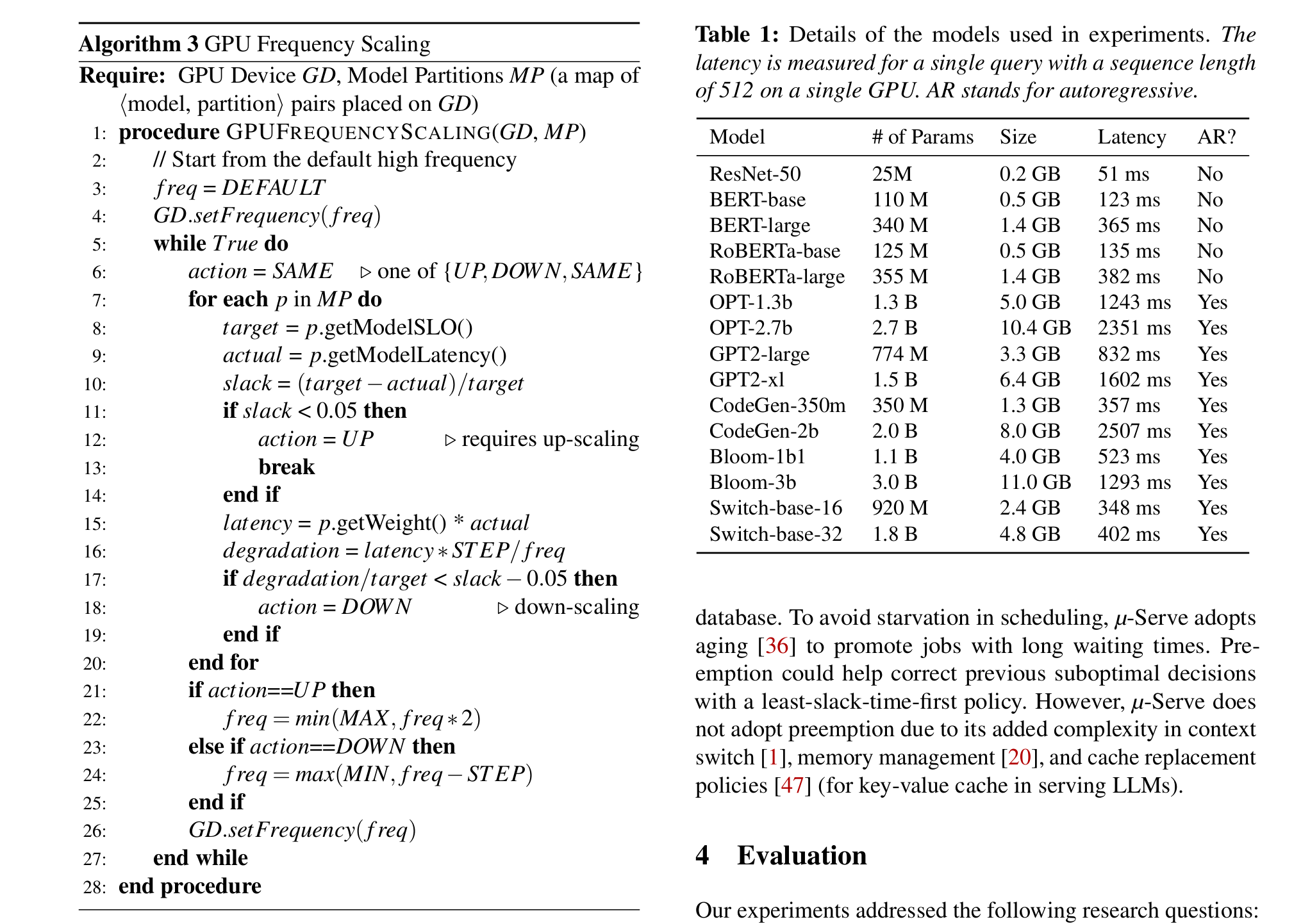
- SLO保持的GPU频率缩放:
- 使用乘法增加-加法减少(MIAD)算法,基于延迟松弛(slack)动态调整频率:保守下调(避免SLO违反)、激进上调(应对负载峰值)。
- 整体架构:离线阶段构建敏感度数据库和分区计划,在线阶段调度请求并监控/缩放频率。
评估结果
- 在8节点16-GPU集群上,使用多种模型(CNN、Transformer、生成模型,如ResNet-50、BERT、GPT2、OPT等)和生产工作负载(Azure和SenseTime traces)测试。
- 相比基线(如AlpaServe),μ-Serve实现1.2-2.6倍功率节省(最高61%减少),在不同SLO严格度、请求率和集群规模下无SLO违反。
- 额外分析:调度组件提升延迟和吞吐量;分区/放置对模型变体鲁棒。
贡献
- 首个结合细粒度操作管理和动态频率缩放的功率感知DL模型服务框架。
- 针对生成模型非确定性的推测调度。
- 开源实现,并基于真实数据集评估。
论文强调功率效率在ML推理中的重要性,适用于同构GPU集群,未来可扩展到异构环境或更多优化(如量化)。整体而言,这是一篇针对实际部署的系统性工作,结合了算法创新和实证验证。
模型服务,就是前向传播
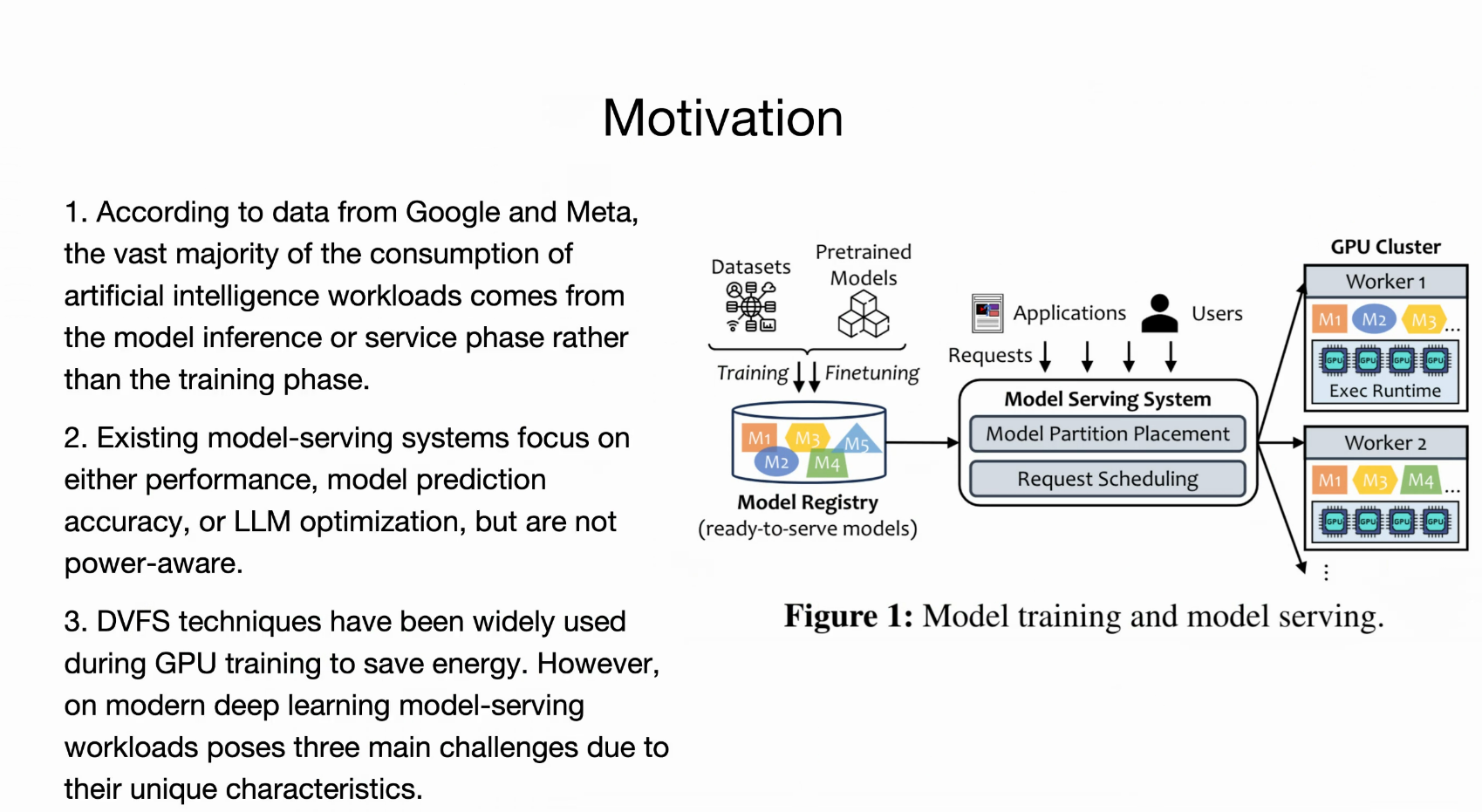
但是,在GPU+LLM Serving 场景下,更不好调度+节能
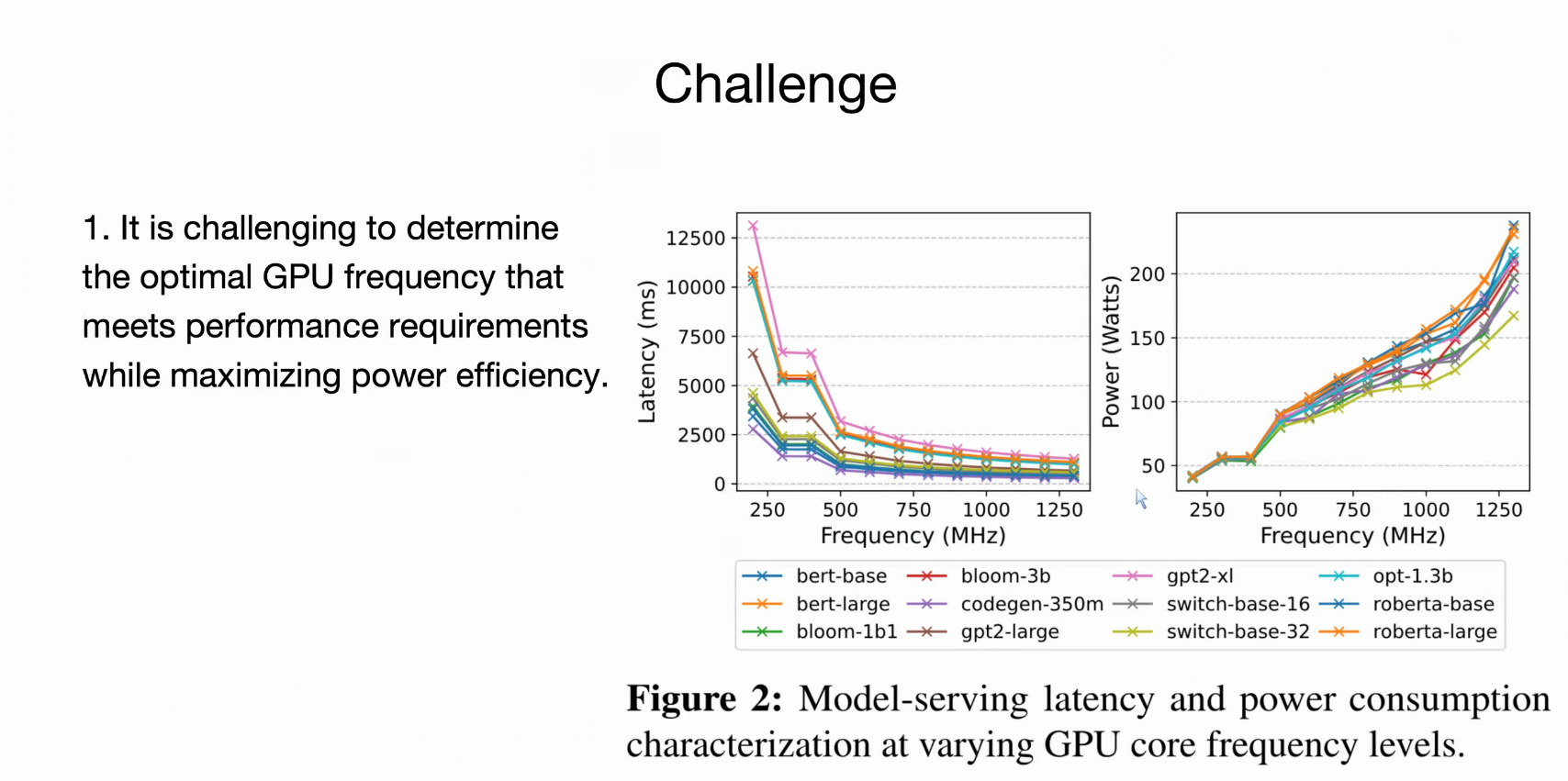
挑战1: GPU频率如何影响服务延迟
这里GPU频率一旦降下来,对延迟敏感型的服务是致命的
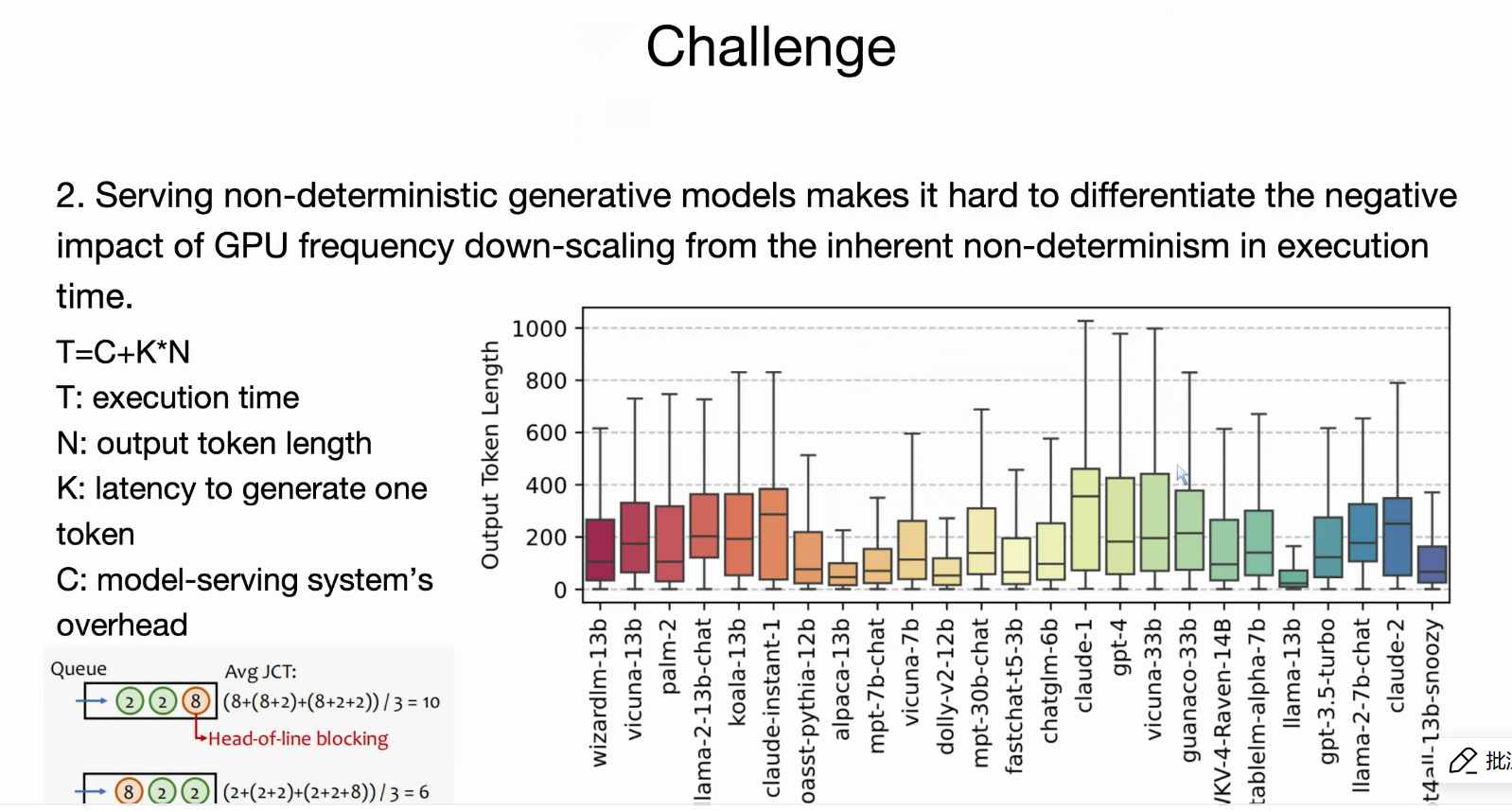
挑战2 生成词长度大小不一,使得我们难以估计GPU降频的影响
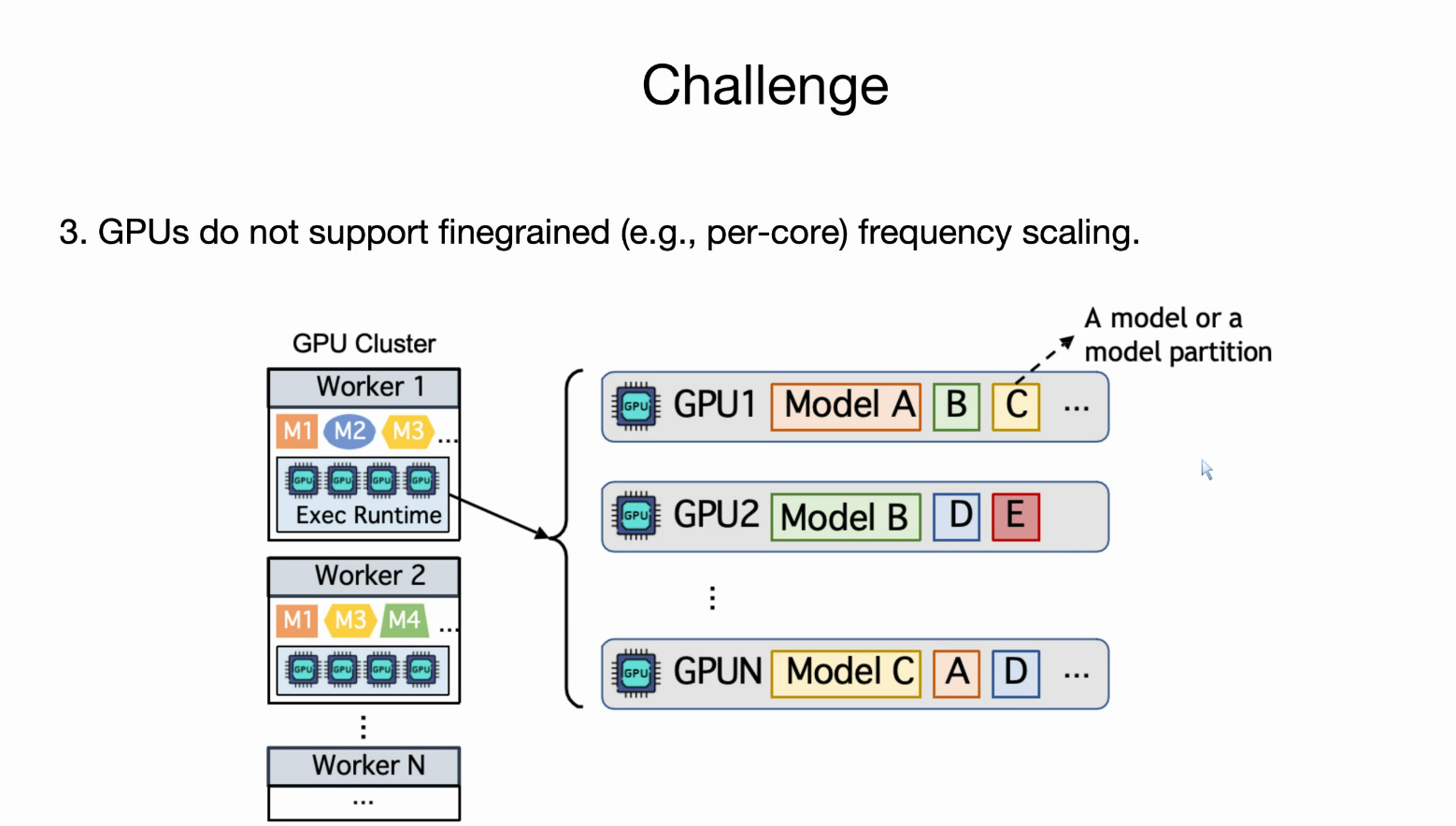
- 挑战3 GPU不能细粒度缩放。A模型放在GPU3,一部分放在GPU1,但是如果你的GPU各自频率不太一样,就会出问题
Design
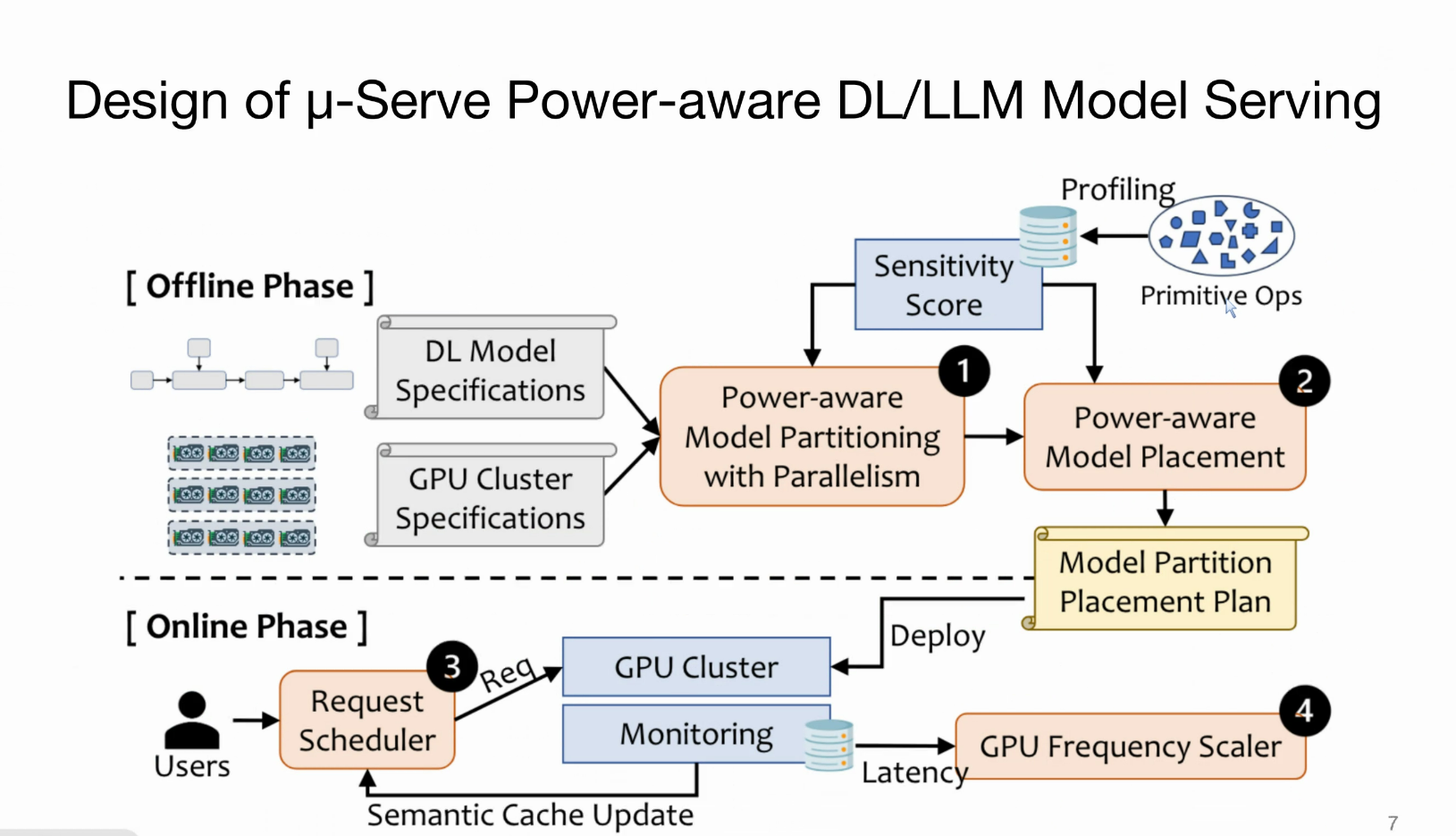
Power aware
尝试把能耗算力敏感度相似的算子的跑放在一个GPU
预处具体的词源有多长
GPU freq scaler
使用乘法增加-加法减少(MIAD)算法,基于延迟松弛(slack)动态调整频率:保守下调(避免SLO违反)、激进上调(应对负载峰值)。
评价
通信粒度,多卡下,感觉还有空间
有的实验对比值得学习跟思考,然后去想瓶颈
PPT做的还不错