
Agent + Website
- Frameworks
- 2026-02-10
- 261 Views
- 0 Comments
- 1709 Words
WebTactix
Semantic Tree-Guided Parallel Multi-Agent Planning for Web Task — 基于语义树引导的并行多代理规划框架。
- 将任务变成搜索树
- Agent并行的BFS去决策完成最佳搜索
任务预处理
将用户请求转换成明确的约束集合,这样可以清晰地检测任务是否完成。
简化观察 (AxTree)
把原始的网页可访问性树转换为简化文本版的 AxTree。
去除重复元素。对重复结构(如评论列表、商品列表)做压缩保留关键信息。
WebTactix 将探索过程组织成一棵树
节点:表示网页状态
边:代表一个操作计划(点击、输入、判断等)
当执行动作产生新页面时,就会在树上扩展一条边并形成新节点。树上保存的信息被用来指导未来的选择。
静态??
在当前页面,WebTactix 会:
- 同时展开多个候选操作(比如多个按钮/输入可能)
- 分配多个规划 agent(智能体)来分别研究每个候选
- 每个 agent 生成:
- 当前页面的事实摘要
- 下一步可执行的计划
这个并行设计可以在更广的状态空间中快速找到高质量方向,而不是像普通脚本那样顺序试错。
为了选择最优路径,WebTactix 引入了决策 agent,它根据事实总结信息和候选计划判断:
- 当前哪个分支最有可能解决任务
- 若某条分支不佳,则:
- 反思 (Reflex):在当前节点重新规划
- 重新选择 (Reselect):从其他候选分支继续探索
执行与记忆更新
选定下一步后:
- 在并行标签页执行计划
- 回放必要的历史操作到对应状态
- 记录执行结果并写回语义树
- 包括“部分完成”“数据提取”等优化策略,
以减少冗余浏览和历史干扰。
方法流程例子:
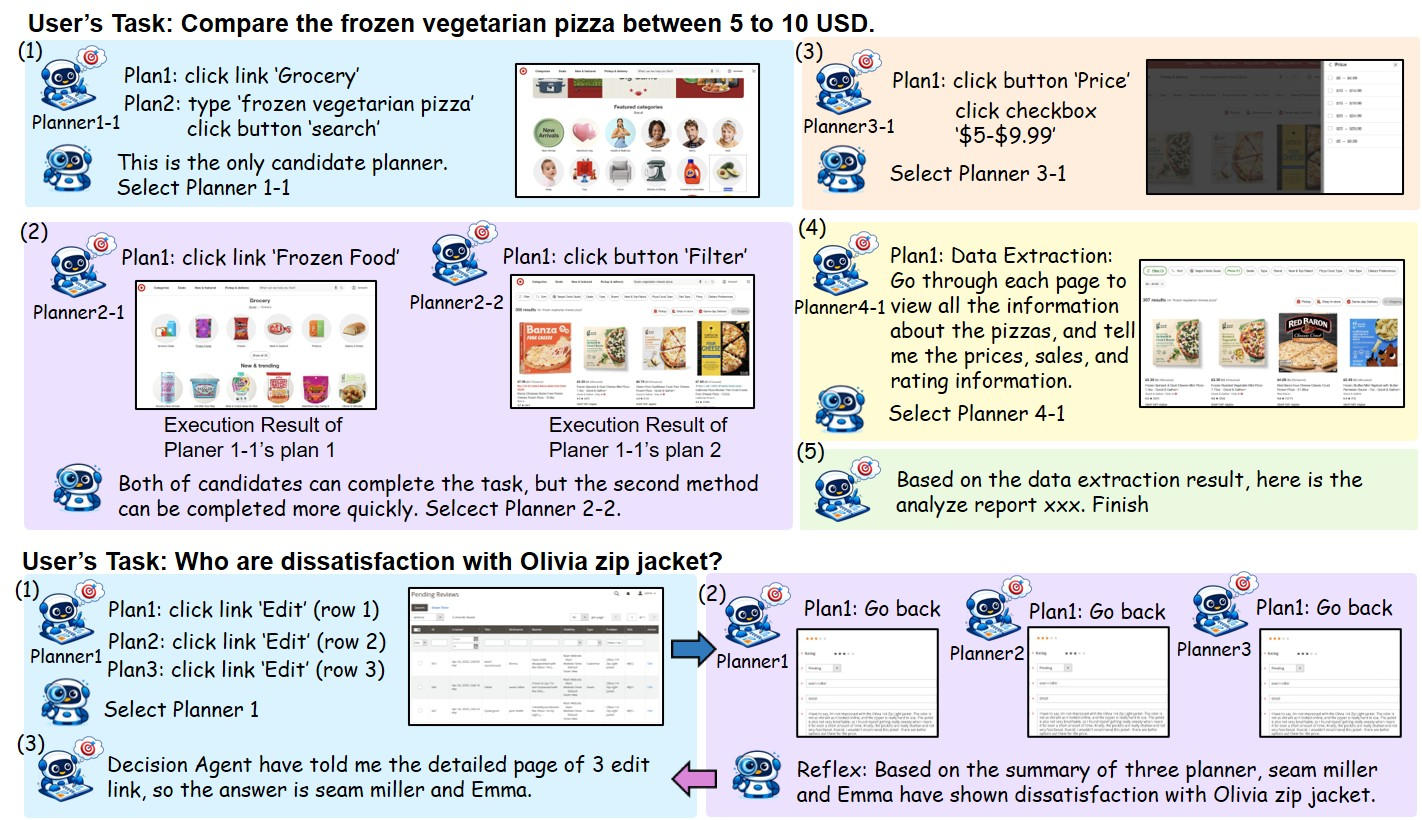
无效搜索??
数据的大量涌入??
这个搜索树,tall & skinny?
相比传统网页自动化或脚本依赖式方法,WebTactix 的创新在于:
✔️ 语义树结构 保留探索过程和事实摘要
✔️ 并行智能规划 agent 加速任务探索
✔️ 决策机制 提升选择质量和探索效率
✔️ 任务可检查性与约束形式化 提高可控性
✔️ 通用性强 适用于不同类型任务(登录、筛查、提取等)
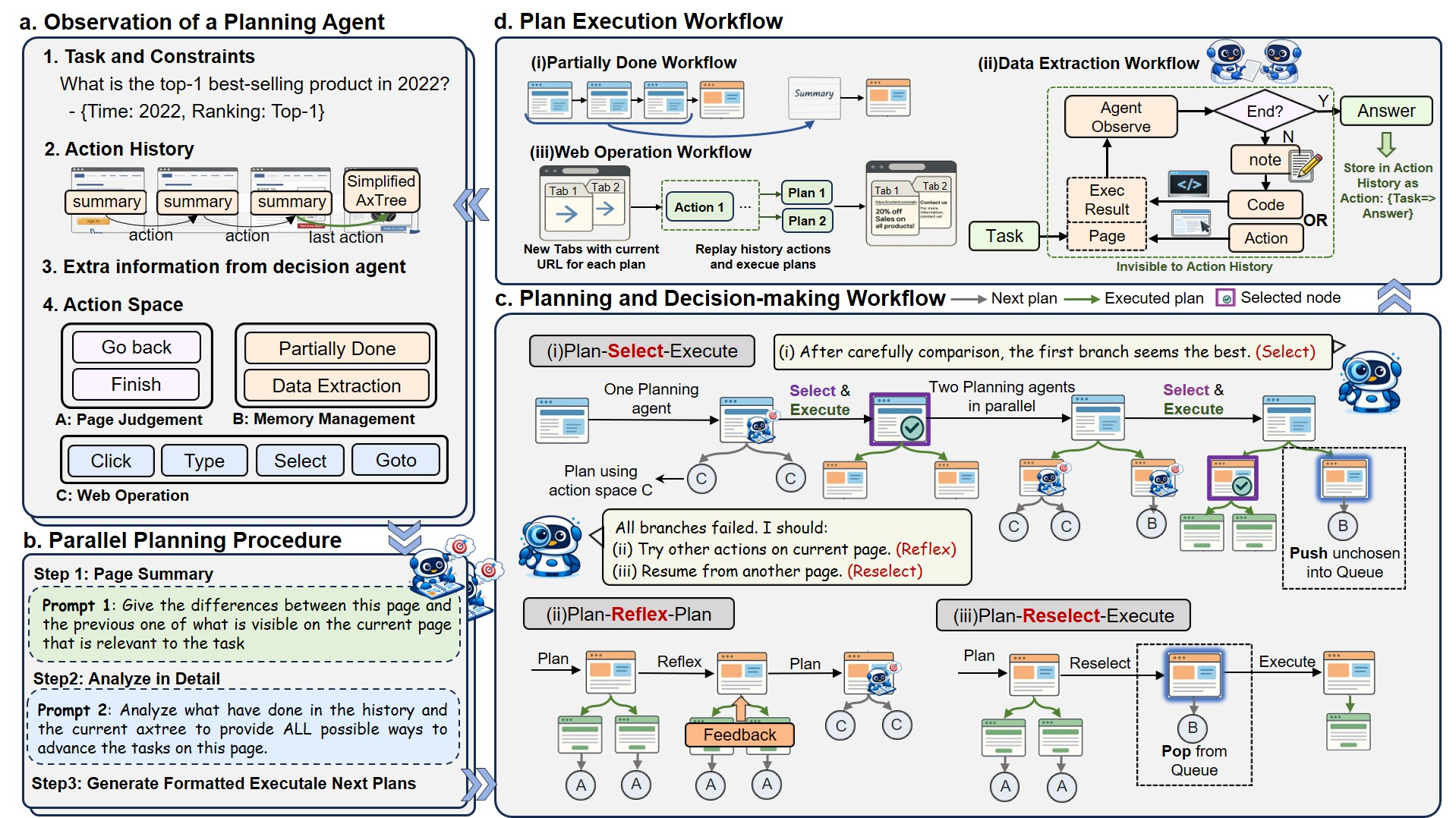
Agent 本体很薄,主要做两件事:
- 把“历史轨迹 + 当前观测 + 指令”交给一个 PromptConstructor 生成 prompt
- 调 LLM 拿到文本输出后,把它解析成可执行 Action(playwright 或 id-based)
Partially Done
- 把“已完成的步骤 + 已确认事实”压缩成更短的摘要
- 目的:减少长历史干扰、提升信息密度(否则上下文越走越长,LLM 更容易跑偏)
Data Extraction
- 需要时反复与页面交互,把结果整理成结构化输出
- 他们还提到“可选用 Python 做数据处理”,并把这段当成一次 action记录回树里
OAgent
https://github.com/codefuse-ai/Oagent/tree/main
- 构建一个能够智能浏览网页、自动完成任务的代理(Agent)。
- 通过大模型结合浏览器自动化技术(如 Playwright),让 Agent 能够“看网页 → 分析 → 执行操作 → 得出结果”。
- 在 WebArena 这样的自动化任务评测环境中达到了 SOTA(State-of-the-Art,最先进)性能,在排行榜上取得高分。
从 README 和代码结构看,它实现了一个多模块的智能 Agent 流程,大致包括以下部分:
- Planner 计划模块
根据当前页面信息和任务目标,决定下一步做什么(比如「点击按钮」「填表」等)。 - Reflector 反思/反馈模块
分析上一步动作是否成功、是否完成了任务,给 Planner 提供反馈。 - Grounder 具体执行定位
是一个视觉语言模型(VLM),根据 Planner 的目标结合屏幕截图输出具体的坐标/操作参数。 - Action 执行层
使用 Playwright 等浏览器自动化库实际执行点击、输入、滚动等操作。 - Summary 结果总结
最终根据整个执行过程的历史生成最终结果。
整个系统形成一个循环:观察 → 计划 → 定位 → 执行 → 反思 → 再计划,类似强化学习或智能体的闭环行为。
核心特点
- 自动化 Web 操作:不只是静态解析网页,还可以自动与页面交互。
- 多角色模型组合:不同模型负责不同任务,如策略生成、视觉定位等。
- 可用于 Benchmark 评测:在 WebArena 这类任务挑战中测试效果。
- 基于 Agent 设计:以 Agent 闭环执行任务,而不是单一步骤调用模型。
典型应用场景
- 自动化完成购物网站流程(填单、搜索、下单等)。
- 自动测试网页 UI 或功能。
- 自动信息抓取与填写。
- 智能模拟用户行为以完成特定任务。
总结来说,这个 Oagent/OpAgent 框架是一个把大模型和浏览器自动化结合起来的智能 Web 操作系统,让 AI 能像人一样通过视觉(截图)观察网页并执行具体操作。
玩策略卡牌游戏可以吗哈哈哈?
VLM这里似乎最重要啊
LLM的实验模型都好小
ColorBrowserAgent: An Intelligent GUI Agent for Complex Long-Horizon Web Automation
https://github.com/MadeAgents/browser-agent.git
长程(long-horizon)网页任务自动化的稳定性和跨站点异构性(site heterogeneity)处理
采用类似 agent + memory + human-in-the-loop 的架构来提高长期浏览任务的表现和适应性
🔹 传统自动化(Selenium、Playwright 脚本)通常是明确编写好命令,但 AI agent 能根据高层指令 智能规划下一步动作。
🔹 “长程稳定性” 指 agent 在执行多步骤任务(例如购买流程、问答检索等)时不掉链子,而且对不同网站结构有更好适应性。
🔹 加入人类反馈循环(Human-in-the-Loop) 提升处理异构站点的能力。
Collaborative Autonomy(协作式自治)
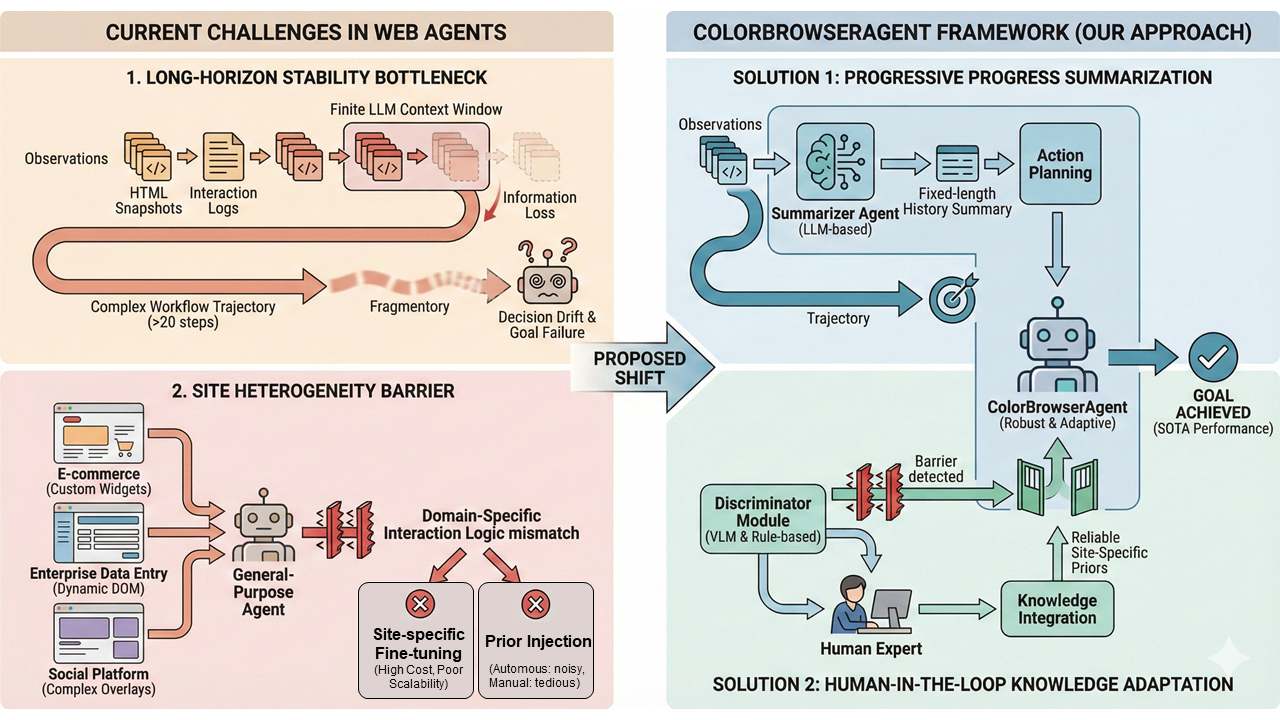
1️⃣ 长任务不稳定(Long-Horizon Instability)
- 真实网页任务往往要几十步
→ 本质:context window 不够 + 无长期记忆
2️⃣ 网站差异太大(Site Heterogeneity)
- 每个网站逻辑都不一样
- LLM 没“常识”
→ 不微调基本搞不定
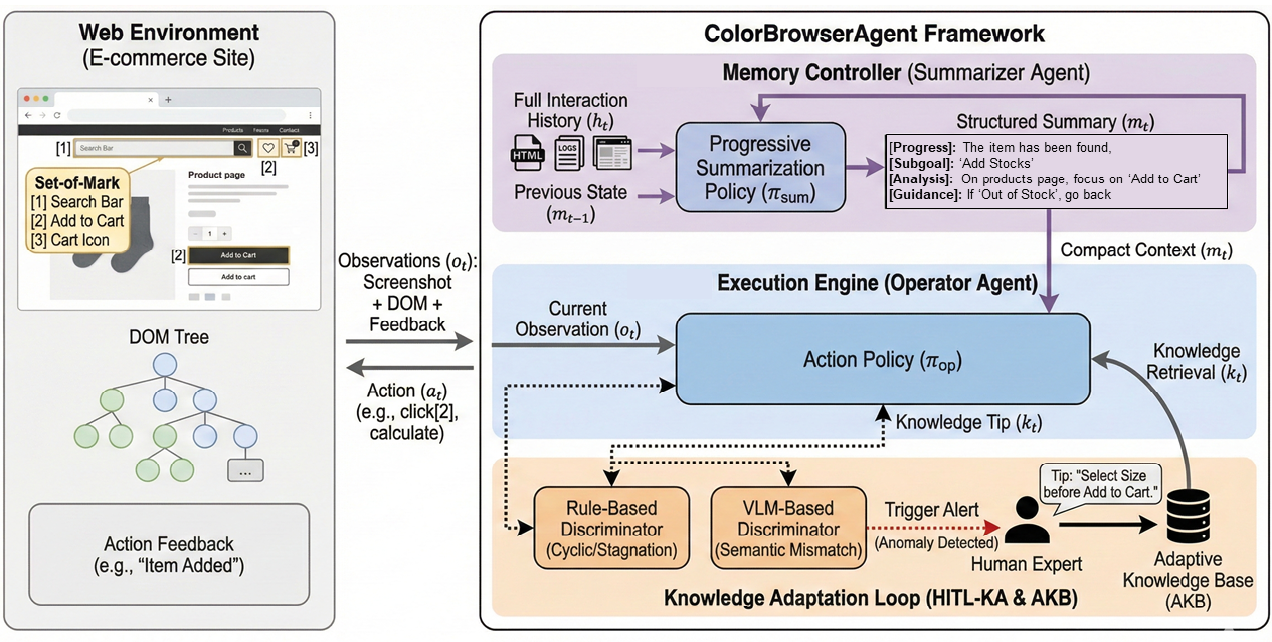
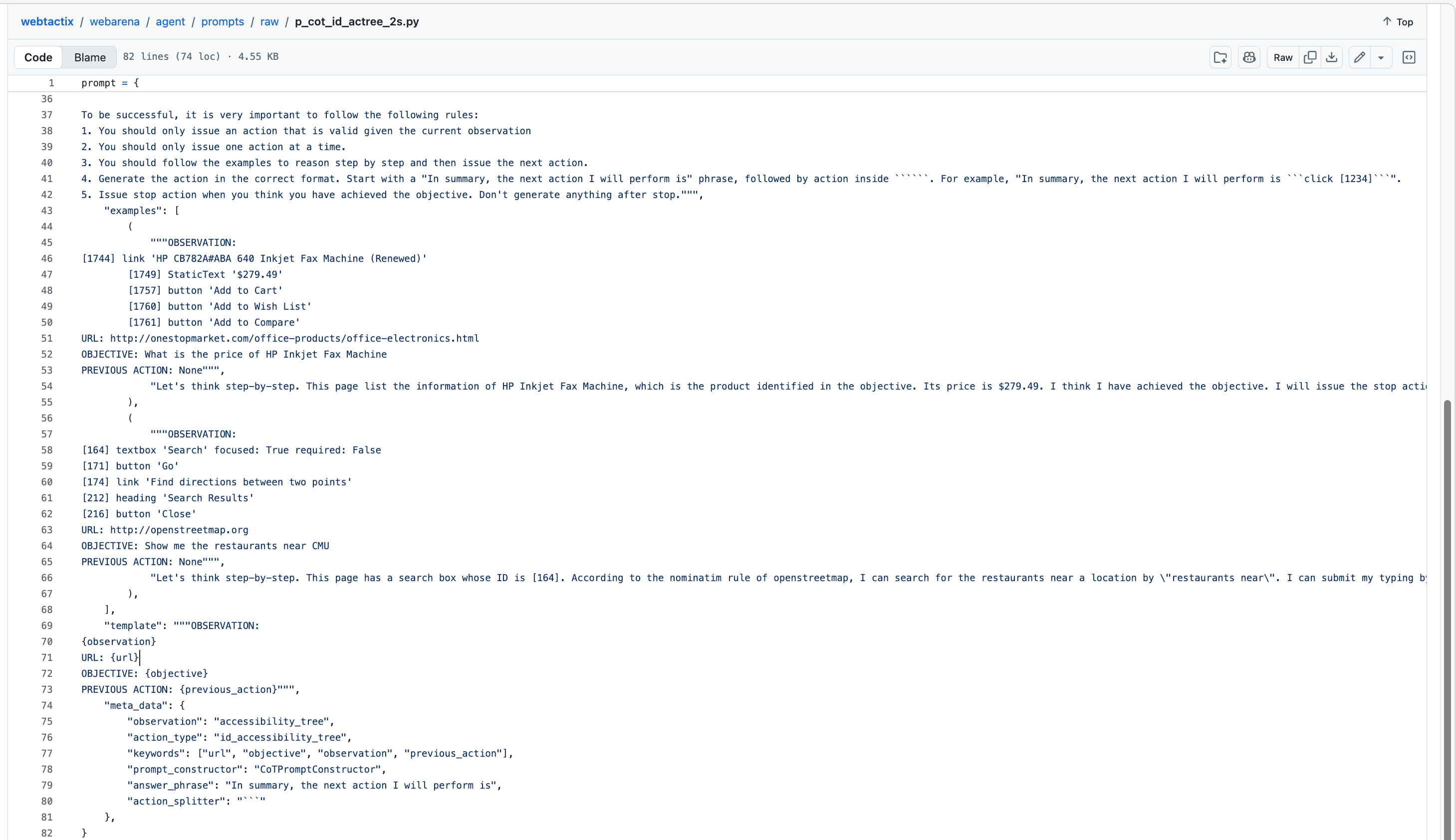
每一步都调用一个 LLM:
总结:现在做到哪了?
WebArena
WebArena is a standalone, self-hostable web environment for building autonomous agents. WebArena creates websites from four popular categories with functionality and data mimicking their real-world equivalents. To emulate human problem-solving, WebArena also embeds tools and knowledge resources as independent websites. WebArena introduces a benchmark on interpreting high-level realistic natural language command to concrete web-based interactions. We provide annotated programs designed to programmatically validate the functional correctness of each task.
一个用于训练和评估自动化智能体在真实网页环境中完成任务的模拟平台。