
Operating System Assignment 7
- OS
- 2024-12-29
- 979 Views
- 3 Comments
- 1418 Words
OpHaibin Lai
12211612
在实验室服务器玩的时候,宕机了5次,Asterinas的profile模式似乎会逐渐把tcp堵死,然后就连不上机器。差点被学长学姐杀了(
本次作业将分成如下几个部分:
- 执行的环境脚本和命令脚本(pipe_lat)
- lmbench测试结果与gdb profiling情况
- OS pipe管道介绍与Asterinas pipe源码学习
- gdb flame graph Observation与Motivation
- pipe_lat优化及其结果
- pipe_lat 拖慢效果
- 我的其他Profile
Docker Image
sudo docker load -i asterinas.tarsudo docker run -it --privileged --network=host --device=/dev/kvm asterinas/asterinas:0.9.4 /bin/bashAsterinas
git clone https://github.com/asterinas/asterinas.git
cd asterinas
make build
# cargo --version # using cargo version 4c39aaff6 2024-11-25 Chosen Script
Then, we first run lmbench with pipe_lat as our script:
./test/benchmark/bench_linux_and_aster.sh lmbench/pipe_latit will return a result:
Running benchmark: lmbench/pipe_lat on linux
The VM is ready for the benchmark.
*** Running the LMbench pipe latency test ***
Pipe latency: 3.0706 microseconds
[ 13.693498] reboot: Power down
Cleaning up...
Benchmark completed successfully.The screenshot of result_lmbench-{Benchmark script directory}.json
![[Pasted image 20241228232809.png]]
we have 3.3424 μs
Generate flame graph
Run:
make profile_server RELEASE=1
# test again: 3.3045 ms
/benchmark/bin/lmbench/lat_pipe
# run 1000 times
seq 1 1000 | while read i; do ./lat_pipe; doneThen reopen a new shell and get into the same container (must as fast as we can), run
make profile_client RELEASE=1We can see the client is observing
![[Pasted image 20241228233511.png]]
As the server is running:
![[Pasted image 20241229043308.png]]
It seems that when gdb is observing, we have a bigger latency.
After gdb running time to the end, we have the svg
![[Pasted image 20241229003233.png]]
![[Pasted image 20241229043820.png]]
And we have the average total running time 10.53 microsecond when gdb running (drawing using matplotlib):
![[Pasted image 20241229044647.png]]
And we have the avg total running time 3.29 microsecond when just running benchmark alone.
![[Pasted image 20241229044542.png]]
Pruning Pipe latency
What is a Pipe in OS ?
In operating systems, a pipe is a mechanism used for inter-process communication (IPC), allowing data to be transferred between two or more processes. It enables one process to send output directly to another process as input without involving temporary storage or intermediate files.
The following figure shows how parent-son process communicate using pipe :
![[Pasted image 20241229034202.png]]
Source code
In asterinas, its code is in asterinas/kernel/src/fs/pipe.rs:
const DEFAULT_PIPE_BUF_SIZE: usize = 65536;
pub fn new_pair() -> Result<(Arc<PipeReader>, Arc<PipeWriter>)> {
let (producer, consumer) = Channel::with_capacity(DEFAULT_PIPE_BUF_SIZE).split();
Ok((
PipeReader::new(consumer, StatusFlags::empty())?,
PipeWriter::new(producer, StatusFlags::empty())?,
))
}Where Channel is a way to implement IPC in asterinas/kernel/src/fs/utils/channel.rs:
/// A unidirectional communication channel, intended to implement IPC, e.g., pipe,
/// unix domain sockets, etc.
pub struct Channel<T> {
producer: Producer<T>,
consumer: Consumer<T>,
}
/// Maximum number of bytes guaranteed to be written to a pipe atomically.
///
/// If the number of bytes to be written is less than the threshold, the write must be atomic.
/// A non-blocking atomic write may fail with `EAGAIN`, even if there is room for a partial write.
/// In other words, a partial write is not allowed for an atomic write.
///
/// For more details, see the description of `PIPE_BUF` in
/// <https://man7.org/linux/man-pages/man7/pipe.7.html>.
#[cfg(not(ktest))]
const PIPE_BUF: usize = 4096;
#[cfg(ktest)]
const PIPE_BUF: usize = 2;
impl<T> Channel<T> {
/// Creates a new channel with the given capacity.
///
/// # Panics
///
/// This method will panic if the given capacity is zero.
pub fn with_capacity(capacity: usize) -> Self {
Self::with_capacity_and_pollees(capacity, None, None)
}
/// Creates a new channel with the given capacity and pollees.
///
/// # Panics
///
/// This method will panic if the given capacity is zero.
pub fn with_capacity_and_pollees(
capacity: usize,
producer_pollee: Option<Pollee>,
consumer_pollee: Option<Pollee>,
) -> Self {
let common = Arc::new(Common::new(capacity, producer_pollee, consumer_pollee));
let producer = Producer(Fifo::new(common.clone()));
let consumer = Consumer(Fifo::new(common));
Self { producer, consumer }
}
pub fn split(self) -> (Producer<T>, Consumer<T>) {
let Self { producer, consumer } = self;
(producer, consumer)
}
And with_capacity, we can find that the IPC allocation is using Vec::with_capacity
pub fn with_capacity(capacity: usize) -> Self {
Self {
slots: Vec::with_capacity(capacity),
num_occupied: 0,
}
}The slots: Vec::with_capacity(capacity) will act as the pipe buffer
Observation
- Original baseline:
![[Pasted image 20241229061059.png]]
Changing the buffer size
Of course, this is the most easy way to improve the performance.
![[Pasted image 20241229050807.png]]
const DEFAULT_PIPE_BUF_SIZE: usize = 32768; // change from 65536 The better script:
The lmbench drop from 3.36 to 3.1739
![[Pasted image 20241229061426.png]]
slow down the performance
为了得分,我先暂时将拖慢Asterinas的执行。
Add some for here
const DEFAULT_PIPE_BUF_SIZE: usize = 65536;
pub fn new_pair() -> Result<(Arc<PipeReader>, Arc<PipeWriter>)> {
let (producer, consumer) = Channel::with_capacity(DEFAULT_PIPE_BUF_SIZE).split();
let (producer2, consumer2) = Channel::with_capacity(DEFAULT_PIPE_BUF_SIZE).split();
let mut x = 0;
for _ in 0..1000 {
//thread::sleep(Duration::from_millis(sleep_time_ms));
for _ in 0..1000 {
x += 1;
}
}
if x > 100000 {
// Ok((
//PipeReader::new(consumer, StatusFlags::empty())?,
// PipeWriter::new(producer, StatusFlags::empty())?,
// ))
}
Ok((
PipeReader::new(consumer, StatusFlags::empty())?,
PipeWriter::new(producer, StatusFlags::empty())?,
))
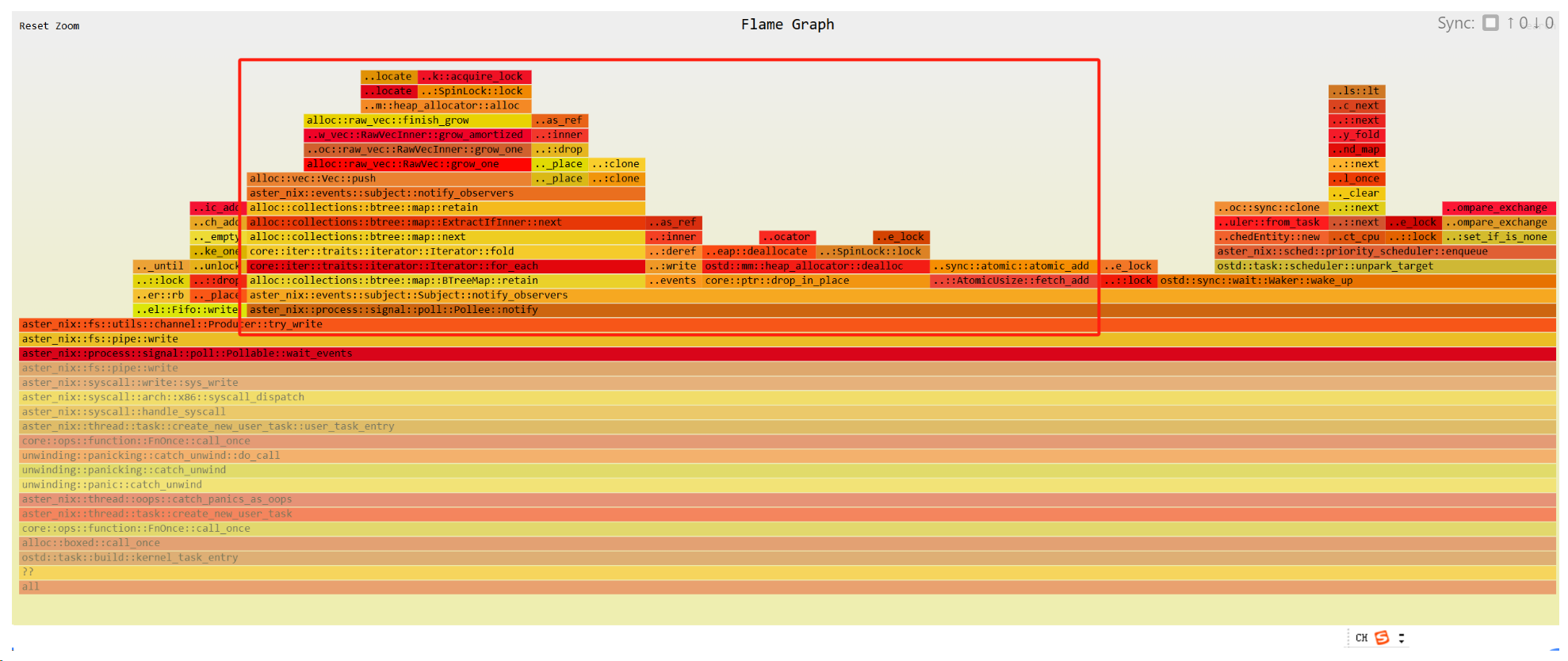
}![[Pasted image 20241229073726.png]]
从图上看,Process::wait变多了,因为需要给管道分配的时间变长了,变成了48sample和24%
![[Pasted image 20241229075021.png]]
而原本是40sample, 20%
![[Pasted image 20241229075143.png]]
出现了更多的page table处理和atmoic::might_sleep
![[Pasted image 20241229075416.png]]
Original
![[Pasted image 20241229075406.png]]
Other possible improvement
由于我的实验室服务器宕机了,我没有来得及测试。但是我分析了热力图
Using Rc instead of Arc
Another bad things happens when we are using Arc: too much atomic operations!
![[Pasted image 20241229052008.png]]
![[Pasted image 20241229060218.png]]
-
Rc(Reference Counted) is for single-threaded scenarios. It uses non-atomic reference counting, which means it only works in situations where all references to the object are guaranteed to be in the same thread.Rcis more lightweight because it doesn't have the overhead of atomic operations. -
Arc(Atomic Reference Counted) is used in multi-threaded scenarios. It is a thread-safe version ofRc, and it uses atomic operations to ensure that reference counts can be safely modified across threads.
use alloc::rc::Rc; // no std
pub fn with_capacity_and_pollees(
capacity: usize,
producer_pollee: Option<Pollee>,
consumer_pollee: Option<Pollee>,
) -> Self {
// let common = Arc::new(Common::new(capacity, producer_pollee, consumer_pollee));
let common = Rc::new(Common::new(capacity, producer_pollee, consumer_pollee));
Self {
producer: Producer(Fifo::new(common.clone())),
consumer: Consumer(Fifo::new(common)),
}
}
![[Pasted image 20241229062405.png]]
![[Pasted image 20241229064735.png]]
But I need to change a lot ........
So I put it in future work since it's FINAL.
impl Consumer<u8> {
/// Tries to read `buf` from the channel.
///
/// - Returns `Ok(_)` with the number of bytes read if successful.
/// - Returns `Ok(0)` if the channel is shut down and there is no data left.
/// - Returns `Err(EAGAIN)` if the channel is empty.
pub fn try_read(&self, writer: &mut dyn MultiWrite) -> Result<usize> {
if writer.is_empty() {
return Ok(0);
}
// This must be recorded before the actual operation to avoid race conditions.
let is_shutdown = self.is_shutdown();
let read_len = self.0.read(writer)?;
self.peer_end().pollee.notify(IoEvents::OUT);
self.this_end().pollee.invalidate();
if read_len > 0 {
Ok(read_len)
} else if is_shutdown {
Ok(0)
} else {
return_errno_with_message!(Errno::EAGAIN, "the channel is empty");
}
}
}use std::rc::Rc;
pub fn with_capacity_and_pollees(
capacity: usize,
producer_pollee: Option<Pollee>,
consumer_pollee: Option<Pollee>,
) -> Self {
// 使用 Rc 来避免多余的原子操作
let common = Rc::new(Common::new(capacity, producer_pollee, consumer_pollee));
// 如果 Fifo 已经很轻量并且不需要跨线程,可以直接传递 Rc
Self {
producer: Producer(Fifo::new(common.clone())),
consumer: Consumer(Fifo::new(common)),
}
}
pub fn split(self) -> (Producer<T>, Consumer<T>) {
// 不需要显式的解构,直接返回值
(self.producer, self.consumer)
}
Future work
change from Vec to smallvec
Another improvement may be using smallvec instead of Vec. It allocate memory on stack.
use smallvec::{SmallVec, smallvec};
pub fn with_capacity(capacity: usize) -> Self {
Self {
slots: smallvec::with_capacity(capacity),// slots: Vec::with_capacity(capacity),
num_occupied: 0,
}
}
smallvec - crates.io: Rust Package Registry
lib.rs - source
![[Pasted image 20241229052534.png]]
I needed to thank you for this very good read!! I absolutely enjoyed every little bit of it. I have got you bookmarked to check out new things you post…
I think what you said made a ton of sense. But, what about this? what if you added a little information? I mean, I don’t wish to tell you how to run your blog, but suppose you added something that makes people desire more? I mean Operating System Assignment 7 is kinda boring. You might glance at Yahoo’s home page and watch how they create news headlines to get viewers interested. You might add a related video or a picture or two to get people excited about what you’ve written. Just my opinion, it would bring your website a little bit more interesting.
Thanks in support of sharing such a good opinion, piece of writing is nice, thats why i have read it entirely